Mon infrastructure en tant qu’hébergeur web indépendant
Je me suis récemment donné comme projet de devenir hébergeur indépendant chez les CHATONS (le Collectif des Hébergeurs Alternatifs, Transparents, Ouverts, Neutres et Solidaires). Étant seul à maintenir les services de mes clients, j’ai dû concevoir une infrastructure sécurisée, performante, scalable, automatisée et facile à maintenir. Je vais à travers cet article vous décrire les étapes à suivre pour monter ce type d’infrastructure.
1. Présentation de l’infrastructure
Dans cette infrastructure, chaque application tourne sous forme d’un ou plusieurs conteneurs répartis sur un ou plusieurs serveurs selon leurs ressources disponibles.
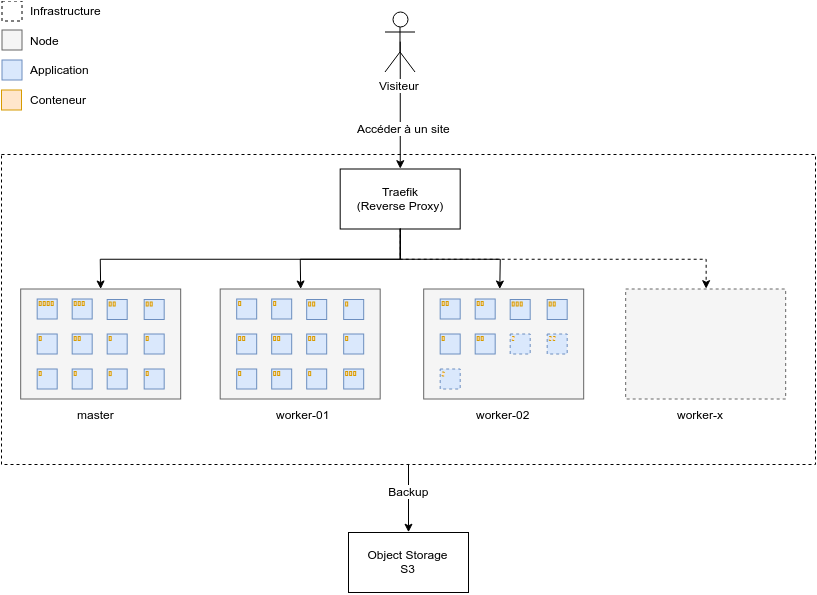
Les conteneurs permettent d’accélérer et faciliter le déploiement des applications, ils contiennent toutes les dépendances d’une application et sont indépendants vis-à-vis de l’infrastructure hôte. Additionné à un orchestrateur, par exemple Docker Swarm, on dispose d’un système qui exécute, coordonne et gère entièrement le cycle de vie de nos applications.
Aujourd’hui je démarre mon infrastructure avec trois petits serveurs, demain elle pourra évoluer facilement suivant l’augmentation des demandes clients.
Plutôt que de gérer mon infrastructure sous forme de tâches manuelles et répétitives, une grande partie est gérée à l’aide de fichiers de définition que je versionne. Dans mon cas, il s’agit principalement de fichiers YAML.
Si jamais tous mes serveurs venaient à être stoppés ou supprimés inintentionnellement, je peux à priori tout restaurer en moins d’une heure du moment que je dispose des backups.
Une fois l’infrastructure mise en place, il est possible de démarrer une application en seulement une ligne de commande, par exemple :
- Un tchat (ex : rocket.chat)
- Un blog (ex : WordPress, Joomla, Ghost)
- Un site e‑commerce (ex : PrestaShop)
- Un espace de stockage (ex : ownCloud, Nextcloud)
- Un système de facturation (ex : Invoice Ninja)
- Un système de monitoring et d’alerting (ex : Grafana + Prometheus + Alertmanager)
Le tout avec un nom de domaine et un certicat SSL associé automatiquement.
2. Déploiement des serveurs
Aujourd’hui je dispose de trois serveurs Ubuntu Xenial chez Scaleway. Un serveur C2S en tant que master et deux serveurs START1‑S en tant que workers. Si vous le souhaitez, vous pouvez commencer avec un seul serveur dans un premier temps. De même, il est tout à fait envisageable de créer ce type d’infrastructure sur votre propre matériel physique si vous en avez les moyens.
Première étape on installe docker sur chaque serveur :
apt-get update; apt-get upgrade; apt-get dist-upgrade;
apt-get install -y apt-transport-https
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
sudo apt-get update; sudo apt-get install -y docker-ceEnsuite, on initialise Docker Swarm sur le serveur master :
docker swarm init --advertise-addr eth0:2377Puis, on joint les serveurs workers au serveur master :
docker swarm join --token <token> <mondomaine.priv.cloud.scaleway.com>:2377Note : Scaleway change les adresses IP privées lors du redémarrage des serveurs. Pour cette raison je dois faire communiquer les serveurs entre eux par leurs domaines privés qui eux restent fixes. Si vous ne passez pas par Scaleway vous pouvez utiliser des adresses IP directement.
3. Persistence des données
Une application stateful, contrairement à une application stateless, a besoin de persister certaines données comme une base de données (des fichiers de configurations ou de simples fichiers images par exemple). On utilise pour ça les volumes docker. De plus, avec Docker Swarm, les containers sont volatiles et ne restent pas toujours reliés à un unique serveur. Il faut donc utiliser un volume driver.
Un espace de stockage flexible
Afin d’éviter d’éparpiller les données et étendre facilement la taille de notre espace de stockage, j’ai créé une partition LVM qui combine plusieurs volumes de données. Au fur et à mesure que l’infrastructure grandit, il est possible d’ajouter nos volumes de données à cette partition.
Avec Scaleway, il est très simple d’ajouter et de relier des volumes de données à un serveur. Une fois nos volumes reliés, nous pouvons les combiner ensemble pour former un seul point de montage.
L’installation se fait sur notre serveur master :
apt-get install -y lvm2
systemctl start lvm2-lvmetad.socket
pvcreate /dev/{nbd1,nbd2}
vgcreate lvm /dev/nbd1 /dev/nbd2
lvcreate -l 100%FREE -n storage lvm
mkfs -t ext4 /dev/lvm/storage
echo "/dev/mapper/lvm-storage /mnt ext4 rw,relatime 0 0" >> /etc/fstab
mount -a
sed -i -e 's/use_lvmetad = 1/use_lvmetad = 0/g' /etc/lvm/lvm.confÀ l’avenir, si vous souhaitez agrandir votre espace de stockage via d’autres volumes, il suffit simplement d’exécuter les commandes suivantes :
umount /mnt
vgextend lvm /dev/nbd3
lvextend -l +100%Free /dev/lvm/storage
resize2fs /dev/lvm/storage
mount -aVolume driver
Le volume driver que j’ai choisi s’appelle docker-volume-netshare. Chaque application persistera ses données sur un serveur NFS.
On installe notre serveur NFS sur notre master :
sudo apt-get install -y nfs-kernel-server
sudo mkdir /mnt/dataPuis on autorise tous les serveurs à s’y connecter :
# /etc/exports
/mnt/data 127.0.0.1(rw,sync,no_subtree_check,no_root_squash) worker-01.priv.cloud.scaleway.com(rw,sync,no_subtree_check,no_root_squash) worker-02(rw,sync,no_subtree_check,no_root_squash)On redémarre notre serveur afin d’appliquer notre configuration :
sudo systemctl restart nfs-kernel-serverPuis on installe sur tous les serveurs le package nfs-common et notre volume driver docker-volume-netshare :
sudo apt-get install -y nfs-commonsudo wget -O /usr/bin/docker-volume-netshare https://github.com/ContainX/docker-volume-netshare/releases/download/v0.35/docker-volume-netshare_0.35_linux_amd64-bin
sudo chmod +x /usr/bin/docker-volume-netshareOn crée un service docker-volume-netshare qui sera lancé à chaque démarrage serveur :
# /etc/systemd/system/docker-volume-netshare.service
[Unit]
Description=Docker NFS, AWS EFS & Samba/CIFS Volume Plugin
Documentation=https://github.com/gondor/docker-volume-netshare
Wants=network-online.target
After=network-online.target
Before=docker.service
[Service]
ExecStart=/usr/bin/docker-volume-netshare nfs
StandardOutput=syslog
[Install]
WantedBy=multi-user.target
systemctl enable docker-volume-netshare.service
systemctl start docker-volume-netshare.servicePour vérifier si tout fonctionne correctement, vous pouvez créer un volume « test » :
docker volume create --driver nfs --name=test --opt share=127.0.0.1:/mnt/data --opt create=truePuis créer un fichier « test » depuis un container :
docker run --rm -v test:/mount alpine touch /mount/testCe fichier devrait apparaître dans le répertoire /mnt/data de votre serveur master.
4. Sauvegardes automatisées
Objectif : Créer un système de sauvegarde journalier de tous les volumes.
Pour sauvegarder nos volumes il nous suffit de sauvegarder notre dossier /mnt/data avec notre outil de backup préféré (borg, restic, duplicity, etc.).
Personnellement j’utilise restic :
wget https://github.com/restic/restic/releases/download/v0.9.3/restic_0.9.3_linux_amd64.bz2
bzip2 -d restic_0.9.3_linux_amd64.bz2
mv restic_0.9.3_linux_amd64 /usr/local/bin/restic
chmod +x /usr/local/bin/resticLe processus de sauvegarde est très simple avec restic :
restic -r <repository> init
restic -r <repository> backup /mnt/dataIl existe plusieurs types de repository : local, s3, sftp, rclone, etc. Personnellement j’utilise s3, car Scaleway propose un Object Storage comme AWS, du coup j’en profite.
On automatise ensuite la sauvegarde avec une tâche cron :
# crontab -e
0 0 * * * /usr/local/bin/restic -r <repository> backup /mnt/dataRestauration
Dans le cas où vous souhaitez récupérer une sauvegarde précédente :
restic -r <repository> snapshots
restic -r <repository> restore <snapshotID> -t restore5. Reverse-proxy et Let’s Encrypt
Objectif : Configurer un reverse proxy pour accéder à nos applications via un unique point d’entrée.
Personnellement, j’utilise Traefik, qui est compatible avec Docker Swarm.
On crée un network que l’on nomme par exemple traefik-net, il sera utilisé pour relier de manière automatique chaque application à Traefik à l’aide des labels.
docker network create --driver=overlay traefik-netPuis on déploie Traefik uniquement sur notre serveur master :
# traefik.yml
version: "3.3"
services:
traefik:
image: traefik
command: --docker \
--docker.swarmMode \
--docker.watch
ports:
- "80:80"
volumes:
- /var/run/docker.sock:/var/run/docker.sock
deploy:
placement:
constraints: [node.role==manager]
networks:
default:
external:
name: traefik-net
docker stack deploy -c traefik.yml traefikEnfin, pour relier une application à notre reverse proxy, on peut créer un service docker avec des labels qui indiqueront à Traefik de diriger le traffic HTTP du domaine blog.ston3o.me sur le(s) bon(s) container(s) :
docker service create --name blog --network traefik-net -l traefik.port=2368 -l traefik.frontend.rule=Host:blog.ston3o.me -l traefik.enable=true ghostLet’s Encrypt
Pour automatiser la création de certificats SSL des services exposés à l’extérieur de mon cluster, j’ai configuré Traefik avec ce fichier de configuration :
# traefik.toml
debug = true
logLevel = "DEBUG"
defaultEntryPoints = ["https","http"]
[entryPoints]
[entryPoints.http]
address = ":80"
[entryPoints.http.redirect]
entryPoint = "https"
[entryPoints.https]
address = ":443"
[entryPoints.https.tls]
[acme]
email = "contact@example.com"
storage = "acme.json"
acmeLogging = true
entryPoint = "https"
onHostRule = true
[acme.httpChallenge]
entryPoint = "http"6. Infrastructure as Code
Toutes les applications sont définies sous forme de code. Un fichier YAML représente tout ce que contient une application (services, volumes, networks).
Voici comme exemple le fichier ghost.yml que j’utilise pour le déploiement de mon blog :
# ghost.yml
version: '3'
services:
web:
image: ghost:2.4.0
volumes:
- ghost:/var/lib/ghost/content:nocopy
environment:
url: ${SCHEME:-http}://${DOMAIN:?err}
deploy:
labels:
traefik.port: 2368
traefik.frontend.rule: Host:${DOMAIN:?err}
traefik.enable: "true"
volumes:
ghost:
driver: nfs
driver_opts:
share: master.priv.cloud.scaleway.com:/mnt/data
create: "true"
networks:
default:
external:
name: traefik-netEn une seule commande, je peux déployer un blog ghost sous le nom de domaine que je souhaite, et avec un certificat ssl automatiquement attribué :
SCHEME=https DOMAIN=blog.ston3o.me docker stack deploy -c ghost.yml blogJ’ai créé d’autres stacks que Ghost, je vous invite à vous rendre sur ce repository si vous désirez en voir d’autres.
7. Monitoring, alerting et logging
Pour monitorer tous mes serveurs, pour être alerté à chaque fois qu’une application ne renvoie pas un code 200 ou qu’un CPU, RAM, Disque dépasse les 95% d’utilisation. Je me suis créé une stack avec grafana, prometheus et alertmanager.
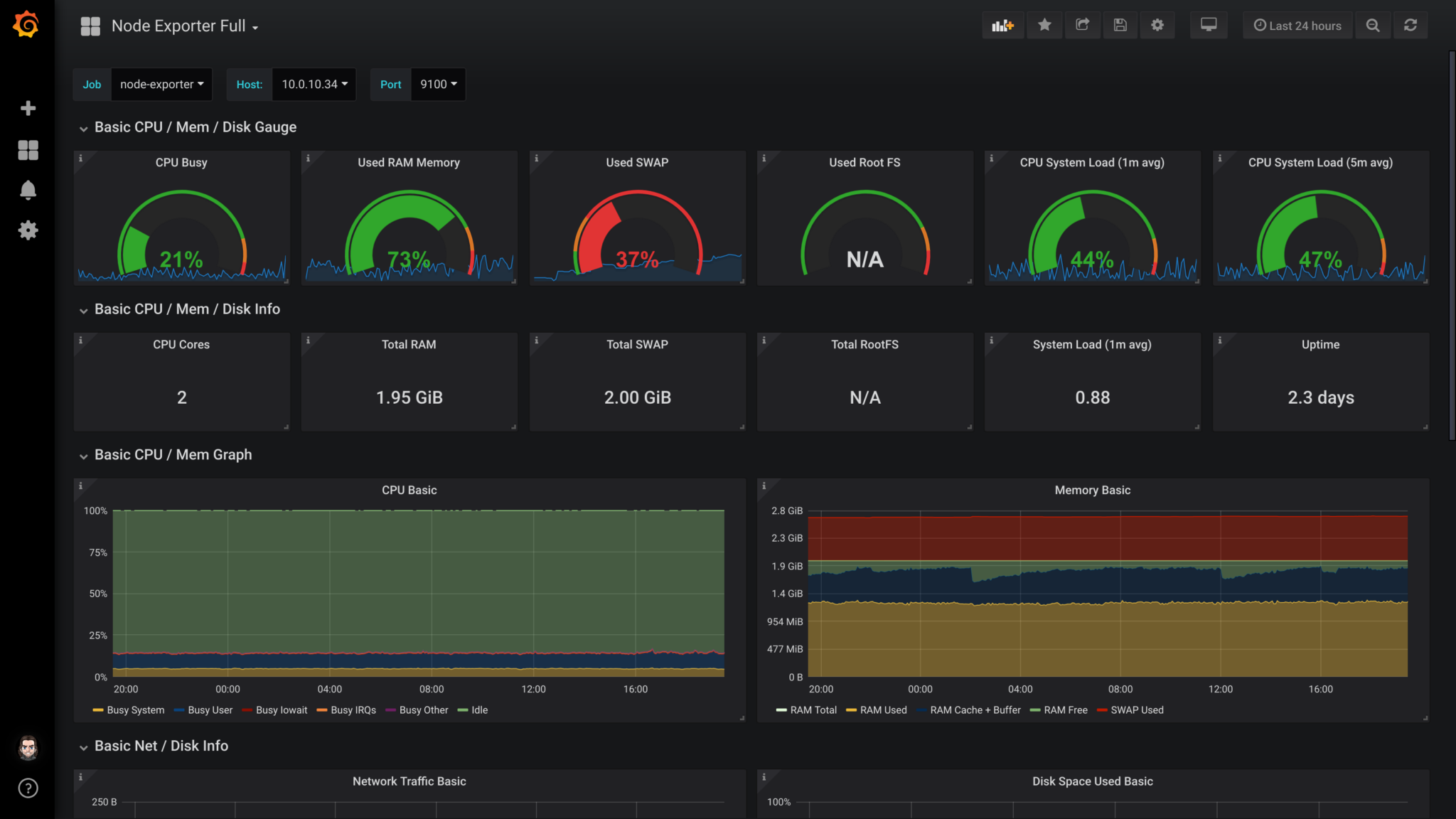
Et d’une commande, je peux tout installer :
DOMAIN_GRAFANA=grafana.mondomaine.fr DOMAIN_PROMETHEUS=prometheus.mondomaine.fr docker stack deploy -c monitoring.yml monitoringLa stack elastic quant à elle, va me servir à logger tout le traffic HTTP entrant sur Traefik et collecter les syslog de chaque serveur.
DOMAIN=kibana.mondomaine.fr docker stack deploy -c elastic.yml elastic8. Sécurité
En termes de sécurité, je provisionne tous mes serveurs avec un playbook Ansible. Concrètement, je configure tous mes serveurs avec un IPS (fail2ban), un firewall (iptables) et des règles de system hardening.
ansible-playbook playbook.yml -u root -i <PUBLIC_IP>,Je crée aussi des règles de sécurité avec les security group de Scaleway, puis des headers HTTP sécurisés pour chaque application :
docker service update <name_app> --label-add traefik.frontend.headers.customResponseHeaders="X-XSS-Protection: 1; mode=block"Conclusion
De manière subjective, c’est la solution idéale pour moi, après avoir testé plusieurs solutions (Kubernetes, Helm, Ark, Ceph, Rook, Minio et Rexray) c’est celle qui dans mon cas est la plus accessible, maintenable, scalable et performante.
Sa scalabilité me permet d’éviter d’investir trop d’argent dans de très gros serveurs et d’évoluer proportionnellement à la demande des clients.
Je pense avoir créé une bonne base, il me reste sûrement encore beaucoup de choses à améliorer, dont par exemple :
- Ajouter des healthcheck et limite de ressource Docker
- Me créer un Siem avec la stack Elastic et Surricata
- Générer de manière aléatoire et automatique les mots de passes dans des docker secrets.
- Auto-héberger toute l’infrastucture à Nancy sur mon propre matériel, pour ne plus dépendre de Scaleway.
N’hésitez pas à me dire dans les commentaires si vous avez des suggestions d’améliorations !
Et vous c’est quoi votre infrastructure de rêve ?
7 commentaires sur cet article
Cyril, le 12 décembre 2018 à 10:28
Bonjour,
Merci pour cet article ! J'aime beaucoup le nom de l'hébergeur. ✌️
Cependant :
Voilà ! ✨
HTeuMeuLeu, le 12 décembre 2018 à 20:42
Bonjour Cyril,
Merci pour ta vigilance accrue. C'est corrigé pour la plupart. Il y a juste pour « Web » où je suis en désaccord. Dixit Wiktionnaire :
Olivier., le 2 février 2019 à 21:01
Remarquable travail de documentation.
Julien, le 24 avril 2019 à 23:19
Travail remarquable et excellent article. Article parfaitement compréhensible et simple d'accès. Cet article va beaucoup m'aider à monter mon petit serveur web :-)
Et grands merci pour la mise à disposition de toute les ressources, c'est un travail colossale.
tant sur la docker que sur ansible.
Longue vie à ethibox
Petre, le 28 août 2019 à 18:37
Bonjour,
Super doc et très claire. J'ai la même infra de test chez moi. Certes elle est scalable mais au niveau de la résilience du docker manager comment fait tu ?
Est ce que tu peux me dire en cas de crash du docker manager comment les flux vont entrer étant donné que traefic dépend fortement du docker manager?
Merci d'avance de ton retour qui pourra m'éclaircir pour un montage vers une infra en production
Cordialement
Johackim, le 15 avril 2020 à 11:10
Merci pour tous vos retours !
Johackim, le 15 avril 2020 à 11:11
Salut Petre,
Niveau résilience, j'ai actuellement un load balancer et 3 docker managers qui ont chacun 1 traefik.
Le reste ce sont des workers.
Comme ça, il peut y avoir un manager qui crash c'est pas un problème ;)
Il n’est plus possible de laisser un commentaire sur les articles mais la discussion continue :