Performance web : l’intégrateur, ce héros
Intégrateur, il est temps de remonter au front !
La discipline a perdu en reconnaissance (et en salaire) alors que l’impact sur la qualité du site est essentiel. Je vais l’aborder par mon domaine de prédilection : la performance.
C’est un domaine suffisamment valorisé côté business pour qu’il ait sa propre conférence française, que Google Search le pousse au rang de critère de référencement, et qu’il existe des équipes dédiées dans des organisations aussi diverses que WordPress, Wikipédia, ou des sites e‑commerce français.
Or l’intégration a largement la main sur l’amélioration de la performance, de l’expérience utilisateur et par extension des revenus.
Car pour qu’un site s’affiche vite et reste fluide, déployer HTTP/3, webpack et de la compression d’images ne suffit carrément pas !
J’ai envie de pousser un concept absolument nouveau : l’amélioration progressive (ah pardon on me dit que ça date de 2003). Au minimum c’est la clé d’un premier affichage éclair car on peut se passer de JavaScript quelques secondes.
Puis abordons le gros sujet des images : comment les charger rapidement, sans toucher aux fichiers eux-même ? Il y a eu quelques nouveautés ces deux dernières années, mais on va voir que même sur des choses que l’on peut croire acquises comme le lazy loading, il y a quelques pièges qui peuvent être contre-productifs.
Enfin terminons avec un petit résumé sur les polices : elles tapent dans l’œil mais il faut en garder le contrôle si l’on veut un bon CLS (une des métriques Google dont on va reparler).
L’amélioration progressive
Cela consiste à utiliser les techniques les plus simples – disons du HTML et du CSS qui marcheraient sur IE 11 – pour, et je cite une présentation de 2003, « focus on information delivery » ou encore « emphasis on web content first ». Du JS (JavaScript) et du CSS / HTML plus modernes peuvent tout-à-fait arriver par dessus pour améliorer l’expérience utilisateur·ice.
C’est la traduction de Progressive Enhancement et oui, c’est le même P que dans PWA mais il semblerait que l’attention se soit concentrée sur l’apprentissage des APIs JS nouvelles plutôt que sur ce vieux concept. La stratégie d’amélioration progressive est pourtant utile à pratiquement tous les sites et applications, là où les Services Workers, IndexedDB et d’autres API sont très spécialisées.
Le respect du concept aurait évité à certains de disparaître des moteurs de recherche en passant à une exécution purement client. Cela élargit la compatibilité à des navigateurs que vous ne testez pas et s’adapte à des situations que votre entreprise ou client ne soupçonne pas. Notez qu’on ne parle pas de supprimer JS, mais de faire sans, au moins pendant quelques secondes. Et évidemment si vous exécutez JS côté serveur, grand bien vous fasse, du moment que vous générez du HTML correct !
Sortir JS du chemin critique
Une amélioration classique en performance est de passer l’intégralité des fichiers JS en asynchrone (attributs defer pour vos scripts, async pour les scripts autonomes). Pourquoi ? Voici une démo, clonée d’un thème shopify, vue par WebPagetest sur une connexion plutôt bonne (12 Mbp/s, 70 ms de latence).
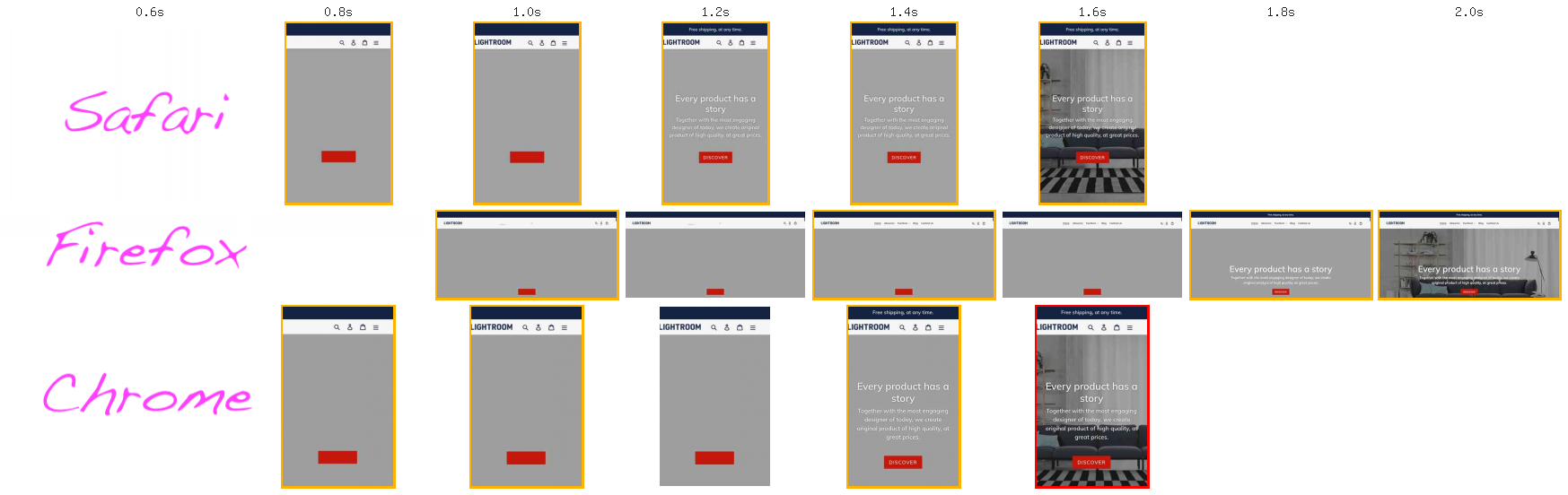
Lire ce qu’il se passe côté réseau est important pour comprendre à quel moment les navigateurs décident d’afficher des pixels.
Bravo, vous êtes au royaume de l’intégrateur : une situation quasi idéale où les deux seules choses qui bloquent encore l’affichage de la page sont des fichiers CSS et HTML. C’est en tout cas la règle générale à connaître, les implémentations navigateur sont un peu plus subtiles et continuent d’évoluer mais on a des outils pour ne pas avoir à s’en souvenir par cœur.
Cette absence temporaire d’interactivité est le moment où le fun commence, je prends un exemple présent sur plein d’interfaces depuis lurette : le carrousel ou slideshow.
🎶 Mon carrousel a du JS, 🎶 mon carrousel a des images
Sache, Ô jeune, que j’implémentais en l’an de grâce 2005 la nouveauté design de l’époque : le slideshow ou carrousel. Il y avait déjà des UX bougons pour nous dire que ça perturbait la lecture et des décisionnaires euphoriques qui évitaient justement de prendre une décision sur quoi mettre en avant en page d’accueil. C’était déjà du Dynamic HTML (JavaScript) et peu après sont sortis des myriades de plugins jQuery qui en accéléraient grandement l’implémentation. La tradition s’est perpétuée jusque dans les frameworks JS modernes.
Qu’est ce que j’ai à reprocher à JS alors que c’est mon métier ?
Ce temps se traduit sur nombre de site par un moment de blanc un peu gênant avant d’afficher l’image, pourtant essentielle d’un point de vue marketing puisqu’on a probablement une bonne raison de vouloir la mettre en avant. Pourquoi ? parce que la plupart des implémentations préfèrent masquer le contenu tant que la bibliothèque ne s’est pas exécutée. J’ai souvent vu des images chargées suffisamment tôt côté réseau mais non affichées ! Sur la démo de Swipe c’est criant : le réseau n’est pas en cause car il n’y a même pas d’image, juste un carré de couleur en HTML/CSS, qui n’apparaît pas tant que la bibliothèque est absente.
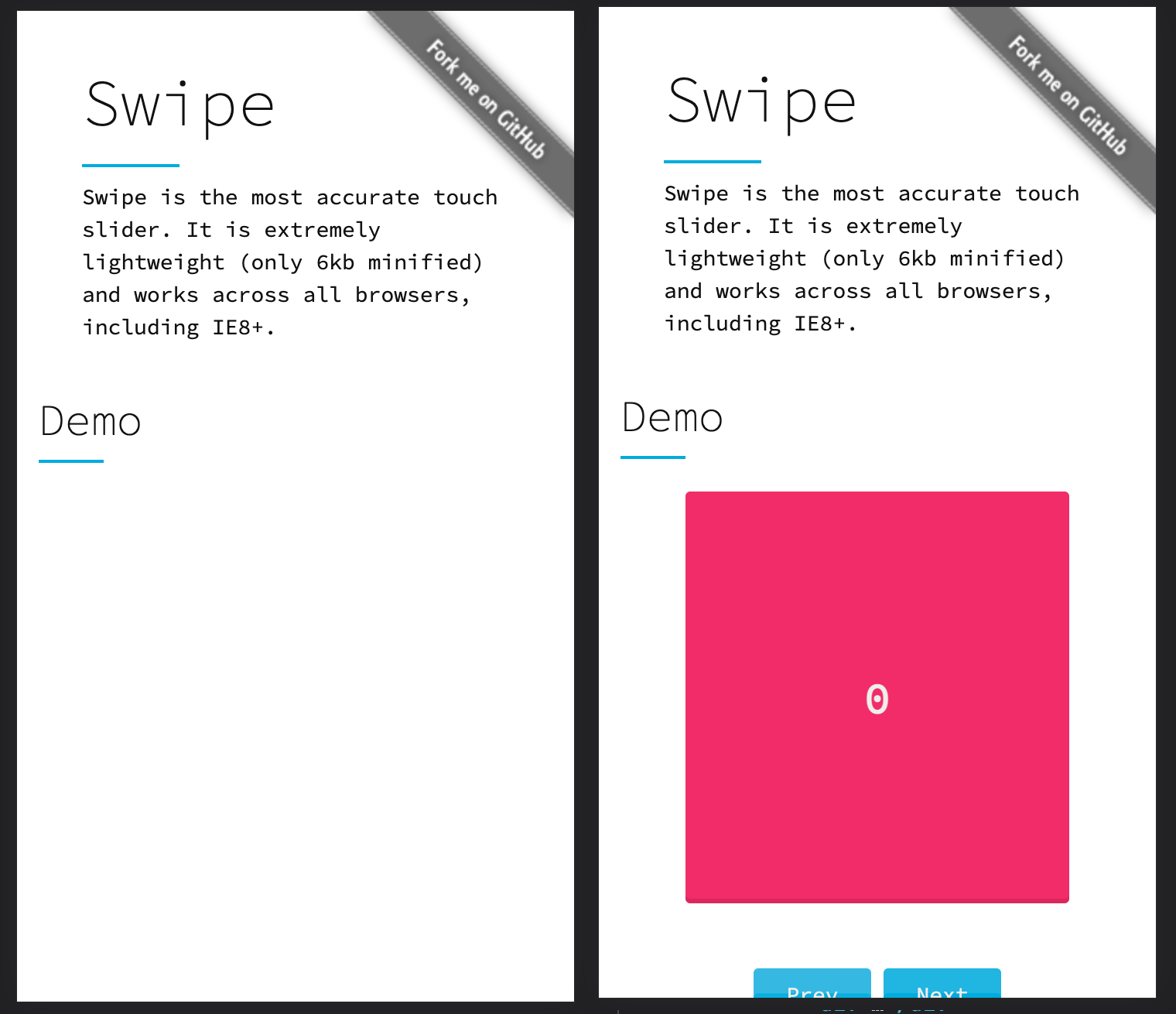
Plus un site sera lourd et complexe, ou plus petites seront la connexion ou la puissance du mobile, et plus visibles seront ces manquements dans l’affichage. Ce qui est rageant, c’est que le contenu est physiquement présent mais on a juste oublié de l’afficher par défaut ! Ici, l’intégrateur consciencieux désactivant JS pendant la phase d’intégration règlera facilement le problème en annulant la règle visibility: hidden; de la bibliothèque, au moins pour la première des slides du carrousel.
On pourrait aller plus loin et proposer des intégrations se passant complètement de bibliothèques JS. La démo suivante d’Anthony Ricaud utilise CSS Scroll Snap et des chatons pour l’effet de transition entre deux slides.
Pas de faux espoirs ici : vous aurez surement besoin de JS pour gérer des éléments d’interface supplémentaires comme des flèches gauche/droite, des points (que nos utilisateurs·rices ne voient pas, soyons réalistes) ou pour démarrer une rotation automatique de contenu, aussi commune qu’embêtante. JS apporte également l’option de faire du lazy loading sur les images non visibles, ce qui est une bonne chose, en attendant que le natif sache faire de même à l’horizontal. Ça arrive sur tous les navigateurs bientôt, y compris Safari.
Pourquoi charger les fichiers JS ?
Certaines fonctionnalités n’ont en fait pas besoin d’être chargées. En tout cas pas là tout de suite, pendant que la page vit son Big Bang : tout est téléchargé et exécuté, ce qui peut bloquer l’utilisateur. Même si les fichiers JS sont en cache, ils vont être entièrement re-exécutés et les technos dites modernes de JS vont avoir tendance à bloquer le processeur de l’utilisateur pendant plus longtemps qu’il n’en fallait pour télécharger le fichier la première fois.
On peut bien sur optimiser son JS, j’y passe d’ailleurs mes journées, mais il existe parfois une autre option : éviter de charger et évidemment d’exécuter des trucs dont on n’a pas besoin. Côté intégration, on va éviter de rentrer trop dans le code JS pour se contenter de l’appeler pile au bon moment. On évite le problème plutôt que de le régler.
Prenons l’exemple d’un sélecteur de date. Évidemment commencez par proposer du natif (champ de type date). Il y a peut-être suffisamment de fonctionnalités pour votre cas : date minimale et maximale, validation de pattern, traduction dans la langue de l’utilisateur, accès facilité en JS et surtout pas besoin de gérer une interface sur mobile puisque ce sont les sélecteurs natifs de l’OS qui seront utilisés. IE 11 quant à lui verra un champ texte que l’utilisateur peut remplir à l’ancienne.
dateAdmettons que vous n’ayez convaincu personne de la beauté de la simplicité ou que objectivement il faille utiliser une bibliothèque JS pour gérer une fonctionnalité complexe comme une plage de date ou un double sélecteur à coordonner. Le ou la dev JS vous sort alors un widget de plusieurs centaines de Ko, écrit en React ou en jQuery, absolument incompressible parce c’est le poids des dépendances et qu’iel n’avait que la demie-journée à y consacrer et qu’iel est déjà parti sur le projet suivant : compresser les images (nous aussi on s’en occupe après).
OK. been there. done that.
Tirons parti du fait que du point de vue d’un utilisateur, on n’a pas besoin de JS là maintenant tout de suite. En fait tant que l’utilisateur·ice ne nous a pas montré qu’iel était intéressé·e par ce champ date, pourquoi est-ce qu’on exécuterait du code par dessus ? Et si on ne l’exécute pas, pourquoi on le téléchargerait ?
Ouvrez l’onglet réseau de vos outils de développement pour la démo suivante : il n’y a que lorsque le champ reçoit le focus que l’on charge le widget, pas avant.
Ici on attend l’événement focus pour récupérer les 2 premières dépendances : un CSS et momentJS. Lorsqu’ils sont là on import() le plugin jQuery dont on dépend (Lightpick) et on l’instancie avec notre code métier. Il y a un petit retard la première fois que l’on clique sur le champ, que l’on peut gommer avec des pré-chargements des fichiers (prefetch, surtout pas preload) et si l’on veut une interface léchée, la vraie difficulté arrive : il faut prévoir un petit design de la phase d’attente.
Les images tardives
Reprenons notre démo Shopify, lorsque nous avons sorti les JS du chemin de l’affichage : si vous regardez les screenshots plus haut, on affiche rapidement du contenu mais le fichier image mis en avant arrive très tardivement à l’écran ! C’est visible sur les outils et il y a des métriques comme le Speed Index et le Largest Contentful Paint pour vous aider à quantifier cette expérience utilisateur. La seconde compte officiellement dans le classement mobile des pages sur Google Search (février 2022 pour le classement desktop).
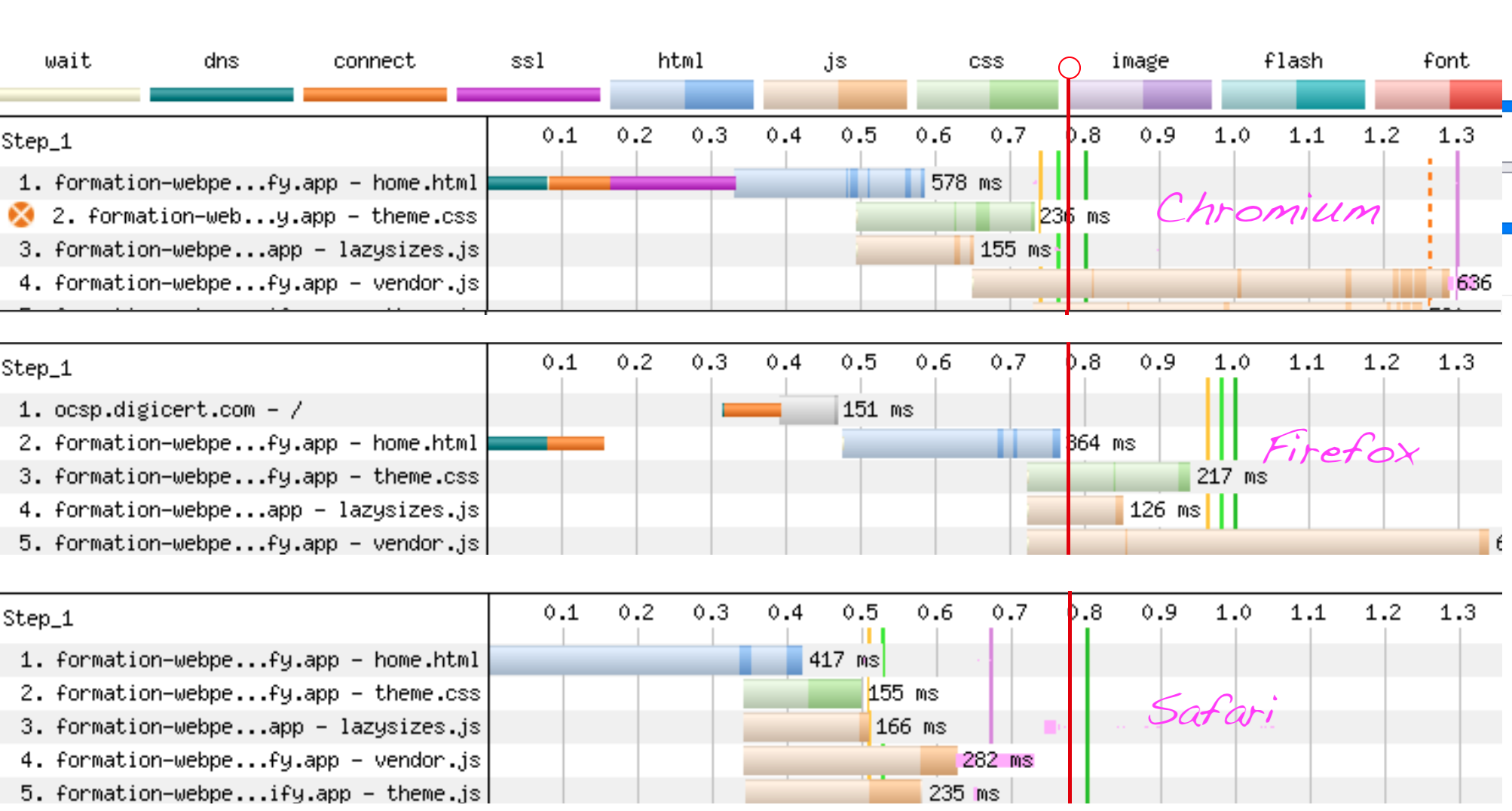
Là encore, il faut regarder ce qu’il se passe côté réseau en cherchant notre fichier image. Deux précisions :
- le nom de l’image finit par Hero-adjusted-2_1950x.jpg
- c’est une image de fond, déclarée dans le HTML :
style="background-position: center; background-image: url(assets/img/Hero-adjusted-2_1950x.jpg);"
Classiquement les images de fond ont une priorité moindre, car d’après la spécification HTML elles sont censées être des images d’apparat, moins importantes que des images de contenu. Le moteur Chromium (les navigateurs Chrome, Edge, Brave, etc…) de son côté a choisi d’être plus pragmatique et de ne pas faire de distinction, seule la position dans le viewport compte, au prix – on l’a vu plus haut – d’un démarrage plus tardif de toutes les requêtes d’images.
L’humble <img src />
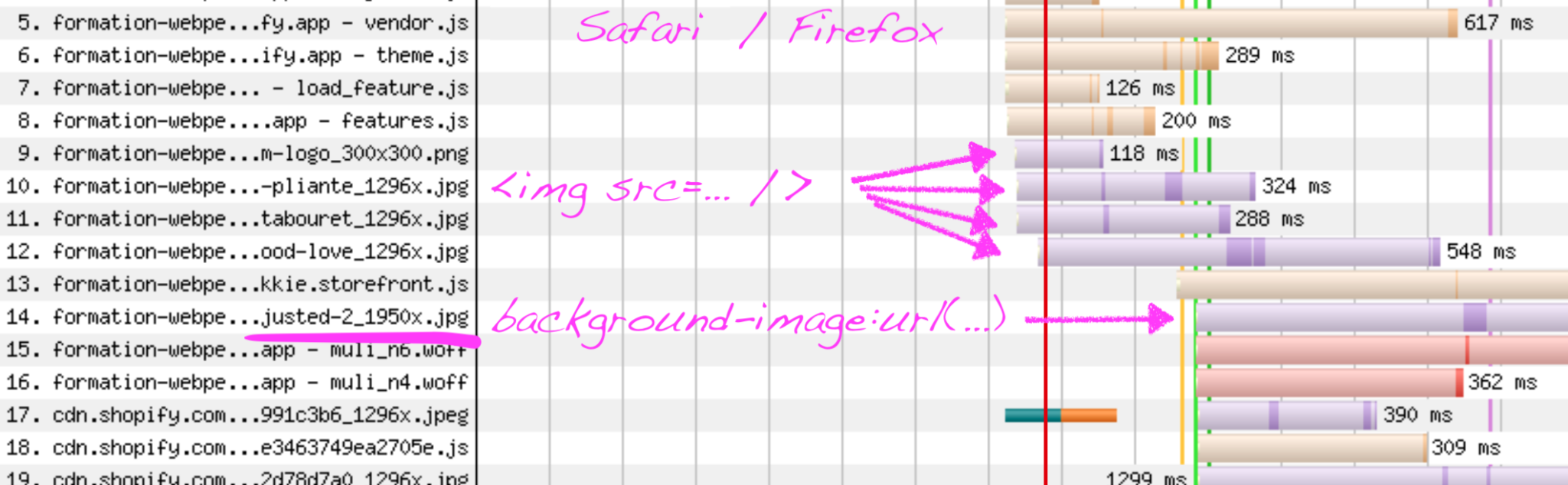
L’intégration choisie ici est une background-image, probablement pour bénéficier de la propriété magique background-size: cover;, qui dans un univers responsive a longtemps été l’option la plus facile pour garantir qu’une image remplissait entièrement la zone ciblée, quel que soit le ratio final d’affichage. Hors Chromium, si on veut accélérer cette image importante, il va falloir en faire une image de contenu avec la bonne vieille balise <img src />. Si vous devez supporter IE 11 ou que vous choisissez la facilité, la correction peut être très rapide :
<img src=Hero-adjusted-2_1950x.jpg style=display:none; />La vie est trop courte pour mettre des guillemets en HTML, mais à part ça vous avez bien lu : on se contente de référencer l’image en HTML, en plus du code CSS déjà déployé, et on la masque. Du point de vue de Safari / Firefox / IE 11 cela suffit à déclencher la requête plus tôt.
Une autre option plus académique est de changer radicalement l’intégration en tirant parti de la propriété object-fit avec la valeur cover. Cela nous donne ceci comme base de travail :
<img src=Hero-adjusted-2_1950x.jpg style=object-fit:cover; />Ça ne marche pas sur IE 11, mais Safari et Firefox commenceront à charger cette image plus tôt que Chromium.
Tenter le préchargement ?
Sur cette page d’exemple, l’image est lourde (350 Ko). Même si le téléchargement commence au plus tôt, l’affichage restera tardif pour des questions d’encombrement des tuyaux numériques. Une solution peut être d’utiliser la directive preload. Elle est censée être une entête HTTP renvoyée par le serveur, mais puisque même notre royaume d’intégrateur a ses limites nous allons utiliser la version HTML avec la très versatile balise <link>.
<link
rel=preload
href="assets/img/Hero-adjusted-2_1950x.jpg"
as=image
/>Avec cela, vous indiquez que votre priorité sur cette page, c’est l’image principale. Voyons le nouveau comportement.

Firefox, Chromium, et Safari s’accordent sur la conséquence : l’image s’affiche effectivement plus tôt… au prix d’un retard sur l’affichage de la page elle-même !
Comment a‑t-on échangé une image plus rapide contre un affichage de page plus lent ? Regardons ce qu’il s’est passé côté réseau.
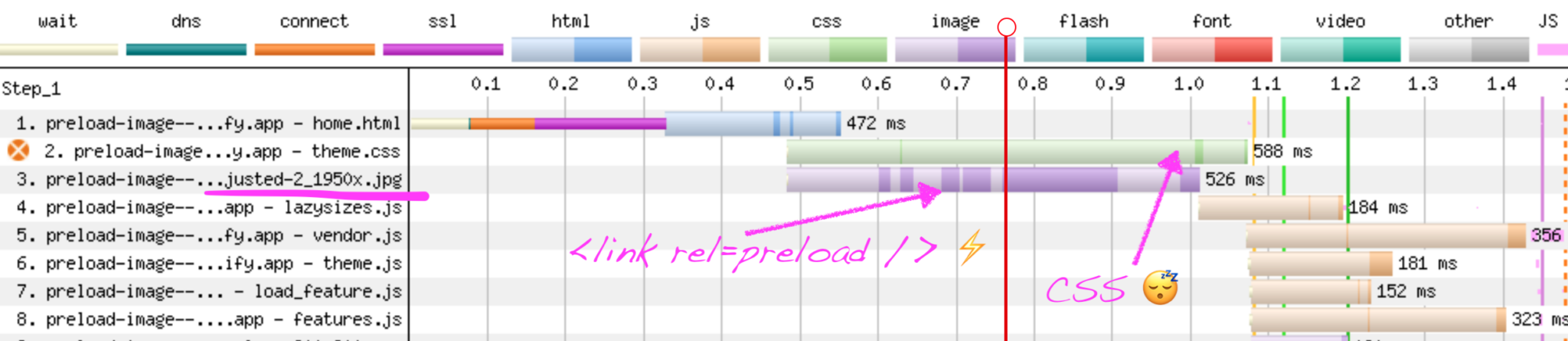
preload marche bien, peut-être tropLes lois de la physique étant têtues, utiliser la directive preload n’accélère pas un fichier, il lui donne une priorité forte par rapport à d’autres fichiers. Mettre un preload sur une image un peu lourde comme ici, c’est donner un peu moins de bande passante à d’autres fichiers. Or certains sont critiques pour l’affichage, comme les fichiers CSS. La bande passante généreuse de 12 Mbp/s de ces tests n’y change rien, à cause d’un mécanisme antique mais vital de TCP qui s’appelle slow start et qui ne permet pas de bénéficier de l’intégralité de la bande passante immédiatement. HTTP/3 fera peut-être mieux mais c’est dans un futur hypothétique.
preload (ou modulepreload) en l’utilisant sur des dizaines de fichiers JS, avec pour conséquence de ralentir l’affichage de la page. C’est visible sur une page et ça se voit même dans des statistiques globales. En passant à une intégration prévoyant l’absence (temporaire) de JS, vous rendez réaliste et même agréable la suppression de ces pré-chargements coûteux. Des frameworks comme NuxtJS permettent de débrayer l’option mais pas Vite par exemple.L’utilisation des préchargements est-elle bonne ou mauvaise ? Ça dépend™, bien sur, et en l’occurrence cela dépendra principalement du poids — et du nombre si vous êtes en HTTP 1.1 — des fichiers à qui vous donnez la priorité.
Priority Hints
⚠️ Fonctionnalité expérimentale Chromium.
Une option moins agressive que preload — qui force réellement le navigateur à charger avant tout un fichier — sera peut-être l’utilisation de la spécification Priority Hints (en brouillon). Elle autorise à mettre un simple attribut importance sur la balise <img>, acceptant les valeurs high, low et auto.
Une valeur high placée sur les images que l’on sait visibles permet à Chrome de ne pas attendre le calcul du viewport pour démarrer le téléchargement, donc de contrecarrer les effets de retard global des images dont nous parlions précédemment, sans pour autant passer en priorité avant le CSS.

Nos tests en production chez Radio France, simulés et chez de vrais utilisateurs, montrent un gain significatif, pour le moment sans contre-partie.
Comment diminuer le poids des images ?
Optimiser une image au mieux est une petite merveille d’ingénierie et demande à connaître finement les anciens formats (JPEG, PNG), leur alternative directe qui va dépendre du contenu même de l’image (PNG par SVG ou bien PNG par JPEG ou bien PNG par AVIF/Webp). Puis vous mettez en branle quelques scripts qui vont automatiquement, en fonction du contenu de l’image, chercher la dégradation la plus acceptable. Et vous devez gérer le support navigateur JPEG, AVIF, pourquoi pas WebP ou JPEG-XL. Tout en expliquant à la Direction Artistique que sur les belles photos JPEG envoyées par les photographes, tout humain aura maintenant un lissage de peau de mannequins de supermarché car vous avez échangé les artefacts de compression JPEG avec ceux de WebP ou d’AVIF. Le lissage de détails est une des astuces de compression forte, mais ce qui passe très bien sur les objets peut être bizarre sur des visages.
Utiliser le responsive à son avantage
Même une image optimisée sans trop se forcer sera plus légère si vous la servez à la bonne taille plutôt que d’essayer de compresser massivement. Prenons une image de 1 200 pixels de large, au format 4⁄3 : vous avez 1 080 000 pixels à encoder. Divisez la largeur par 2, et vous n’avez plus que 270 000 pixels à encoder, c’est quasiment une division par 4. Dans la pratique le poids d’une image compressée serait divisé environ par 3 ce qui est un facteur d’amélioration largement au dessus des meilleurs algos de compression.
Design responsive
Si vous ne devez pas afficher le même contenu visuel en fonction du viewport, c’est une super opportunité ! À condition d’éviter certains pièges classiques.
Une recherche rapide sur les composants responsive m’a amené sur la ressource Google web.dev/new-responsive . Le modèle d’article prévoit d’afficher une image d’illustration sur la version écrans larges et rien du tout sur mobile.
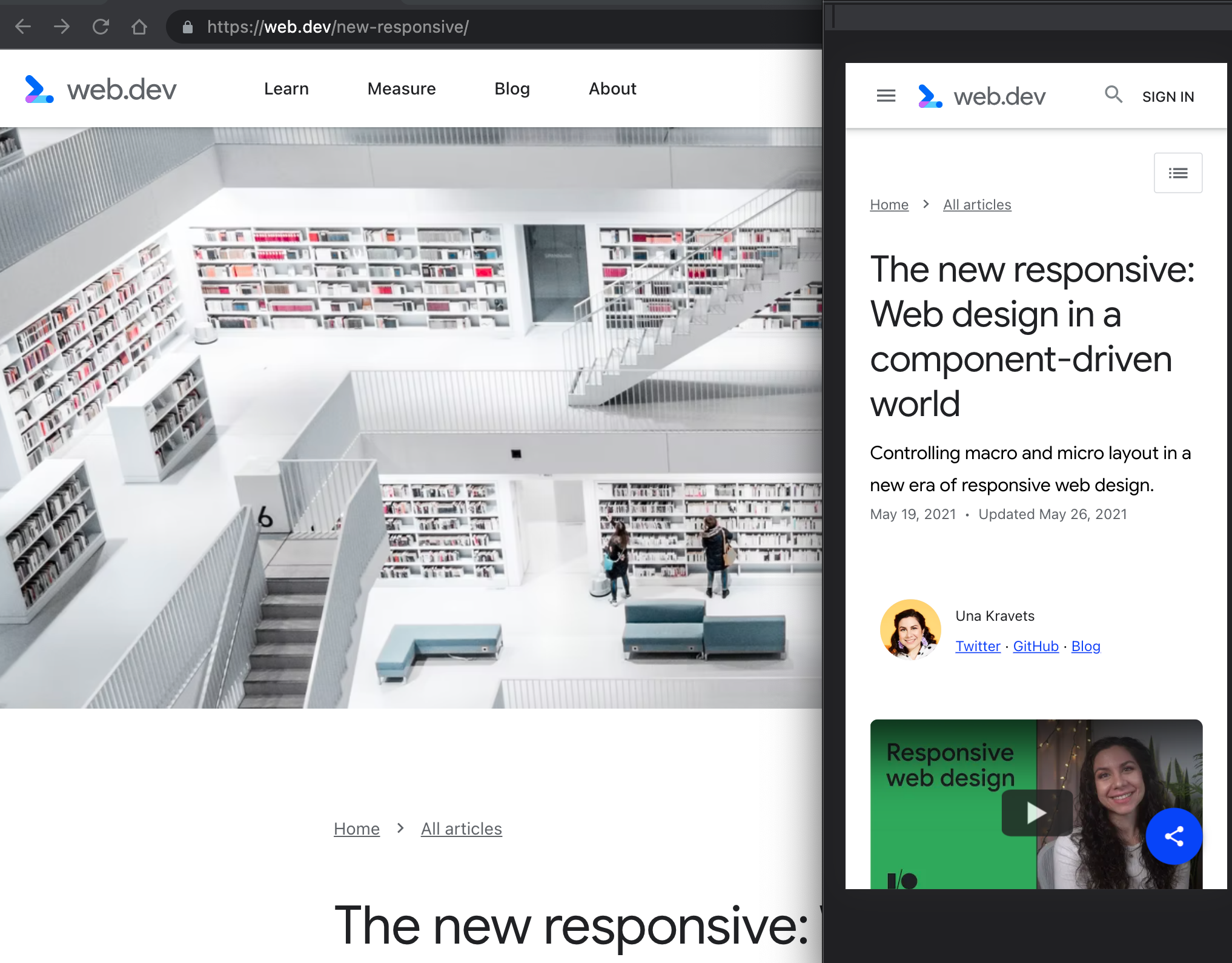
Cette intégration se fait souvent soit en utilisant CSS background-image, soit en référençant l’image avec notre bonne vieille balise <img>. Dans les deux cas une manière simple d’intégrer ce design est de cacher l’image avec display:none; lorsque le viewport est sous une certaine valeur. Le modèle d’article ici a fait ce choix mais cela fait charger aux mobiles une image de haute qualité (autour de 200 Ko). Utilisons les media queries un peu mieux pour éviter cela.
En CSS
Si l’intégration avait été faite en CSS seulement, rien de plus facile.
/* ❌ NE FAITES PAS */
.w-hero {
background-image: url(…);
…
}
@media (max-width: 480px) {
.w-hero {
display: none;
}
}
/* ⚡️ PRÉFÉREZ */
@media (min-width: 481px) {
.w-hero {
background-image: url(…);
…
}
}
@media (max-width: 480px) {
.w-hero {
display: none;
}
}On fait en sorte de ne pas utiliser background-image en dehors de la condition de viewport et les navigateurs ne déclencheront pas la requête. De la même manière on pourrait augmenter la largeur (et donc la qualité et le poids) de l’image en fonction du viewport.
HTML
Référencer l’image en HTML est souvent une meilleure idée qu’en CSS car cela permet de démarrer les requêtes plus tôt (sauf Chromium), donne accès au lazy loading et nous permettra de proposer plusieurs dimensions d’image. C’est d’ailleurs le parti pris de l’intégration ici, mais comment éviter un téléchargement d’image ? Hé bien nous avons également accès aux media queries en HTML !
Dans la démo ci-dessus, vous devez utiliser le niveau de zoom à 0.5 pour voir l’image être affichée. Si vous regardez ce qui transite sur le réseau, vous verrez qu’elle n’est téléchargée qu’au-delà d’un viewport de 481 pixels de large.
On est passé du classique <img> à la structure <source> qui nous permet d’appliquer une condition de chargement. La balise <img> finale est nécessaire pour porter les attributs comme les noms de classe, et enfin nous avons sciemment omis l’attribut src.
Si vous devez supporter IE 11, il vous faudra rajouter un src valide, mais également la ligne suivante, toujours dans l’idée de ne pas télécharger quoi que ce soit sur les navigateurs modernes :
<source media="(max-width: 480px)" srcset=data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAEAAAABCAQAAAC1HAwCAAAAC0lEQVR42mNkYAAAAAYAAjCB0C8AAAAASUVORK5CYII= >De la même manière qu’on a évité une requête, on pourrait utiliser les media queries pour charger des images plus ou moins grandes en fonction du viewport. Mais si le design ne varie pas, on va utiliser une autre technique.
Design unique
On veut proposer le meilleur ratio qualité / poids à l’utilisateur. Pour cela nous avons besoin d’informations que détient le navigateur : le viewport et le Device Pixel Ratio ou DPR. En JS on a accès à window.devicePixelRatio et window.innerWidth mais encore une fois pourquoi attendre une exécution de script ?
HTML a prévu le coup : on va lister au navigateur ses options de dimensions dans l’attribut srcset, il va multiplier le DPR par le viewport et charger l’image la plus proche.
Sur cette démo, la dimension de l’image choisie est affichée : jouez avec la largeur de votre fenêtre ou avec le niveau de zoom de codepen pour voir le choix fait par le navigateur.
Erreur fréquente : n’oubliez pas de renseiger l’attribut sizes ! Par défaut le navigateur pense que vous voulez afficher l’image sur toute la largeur, quelles que soient les règles que vous auriez écrites en CSS (en fait le fichier CSS n’est peut être même pas encore là). Si votre design a prévu une largeur d’affichage plus petite, il faut dupliquer les règles dans cette attribut, à la syntaxe pas piquée des hannetons.
Le lazy loading
Si on part du principe qu’il n’y a pas plus léger qu’une image qui n’a pas été téléchargée, on peut se dire qu’appliquer le lazy loading, natif tant qu’à faire, sur les images est une bonne idée.
<img src=chatons.jpg loading=lazy />Ça marche partout sauf sur IE 11 et Safari (promis ça arrive bientôt). L’absence de support signifie seulement l’absence d’optimisation : l’image s’affiche quand même, au contraire des solutions basées sur JS pour lesquelles il fallait prévoir un fallback <noscript>. L’autre avantage du natif ? Les images sont prises en compte avant que la bibliothèque ait eu le temps de commencer à s’exécuter.
Viennent alors les deux problèmes courants dans les implémentations que j’ai vues.
Pas sur toutes les images !
Cela semble évident une fois qu’on a le nez dessus, mais mettre du lazy loading sur TOUTES les images est une mauvaise idée : vous ralentissez l’affichage des images du viewport, et c’est encore pire si vous faites du lazy loading en JS ! Côté natif WordPress l’a fait et a dû revoir son implémentation simpliste en voyant les indicateurs CWV de Google aller dans le rouge. Iels permettent maintenant de personnaliser les cas où le lazy loading ne doit pas s’appliquer (ticket) pour garder une valeur de LCP correcte.
En attendant que ça charge…
Que votre image soit en lazy loading ou pas, si votre site est optimisé pour l’affichage rapide, il y a un moment où l’image n’est pas encore physiquement arrivée jusqu’à l’utilisateur. Le navigateur affiche ce qu’il peut à la place de l’image, et à priori ça sera pas terrible si vous ne lui dites pas quelle est sa dimension d’affichage finale.

Visuellement c’est déjà moyen au premier affichage mais le pire est à venir : au fur et à mesure que les largeurs / hauteurs sont découvertes dans les metadonnées des fichiers image, le layout est recalculé pour laisser la place à l’image. Les contenus sous ces images se font bousculer, sous les yeux meurtris de l’utilisateur. Google mesure d’ailleurs ce comportement avec la métrique Cumulative Layout Shift, qui compte officiellement dans le classement des sites.
La responsabilité de l’intégrateur est donc de prévoir l’espace. Dans un design responsive, on peut utiliser trois techniques, qui partent du principe que vous utilisez height:auto; en CSS.
- Vintage : on bricole une image avec un poids minuscule, qui a le bon ratio (outil) et qu’on utilise comme placeholder, c’est-à-dire en remplacement en attendant que la vraie image arrive. J’ai épaté mes clients 10 ans avec ça !
- En HTML pur, en définissant les attributs
widthetheightde l’image. Dans un rare alignement des implémentations, Safari, Chrome et Firefox interprètent maintenant de la même manière ces attributs : ils l’utilisent pour calculer le ratio de l’image qui va être utilisé pour calculer la hauteur. D’ailleurs vous n’avez même pas l’obligation d’y mettre les dimensions physiques de l’image. Si le ratio est respecté, cela suffit !<img src=chatons.jpg width=16 height=9 loading=lazy /> - En CSS : le support de la propriété aspect-ratio est suffisamment large depuis 2021 pour l’utiliser en production. Elle peut vous sortir de situations où HTML
widthetheightne suffisent pas : lorsque vous avez un design qui prévoit des ratios différents en fonction du viewport. Exemple :
@media (orientation: portrait) {
.hero img { aspect-ratio: 1 / 1; } /* image carrée si le device est vertical */
}
@media (orientation: landscape) {
.hero img { aspect-ratio: 16 / 9; } /* image large */
}
Pour revenir sur l’exemple de WordPress : ils sont passés de l’application inconditionnelle du lazy loading sur toutes les images à une détection de la présence des attributs width et height pour éviter de mauvais scores CLS (ticket).
Images cachées dans les méga menus
Parfois vous verrez sur le réseau des images qui ne sont pas affichées immédiatement mais qui prennent néanmoins leur quota de bande passante. C’est le cas des images planquées dans des méga menus dépliables.
Pour la démo, une recherche rapide sur le mot clé « méga menu » m’a amené sur le site megamenu.com qui se trouve être un plugin WordPress. Peu importe la techno, l’implémentation qui nous intéresse ici est classique : si une image doit apparaître dans un sous-menu, on la déclare en HTML. Ici, c’est une banane.
<li class='mega-menu-item mega-menu-item-type-widget widget_maxmegamenu_image_swap mega-menu-item-maxmegamenu_image_swap-2' id='mega-menu-item-maxmegamenu_image_swap-2'>
<img class='mega-placeholder' src='banana-150x150.png' />
</li>À partir du moment où le parser HTML voit <img src> la requête sera faite. Sur Safari et Firefox on voit les images cachées se charger et contribuer au ralentissement de l’affichage.
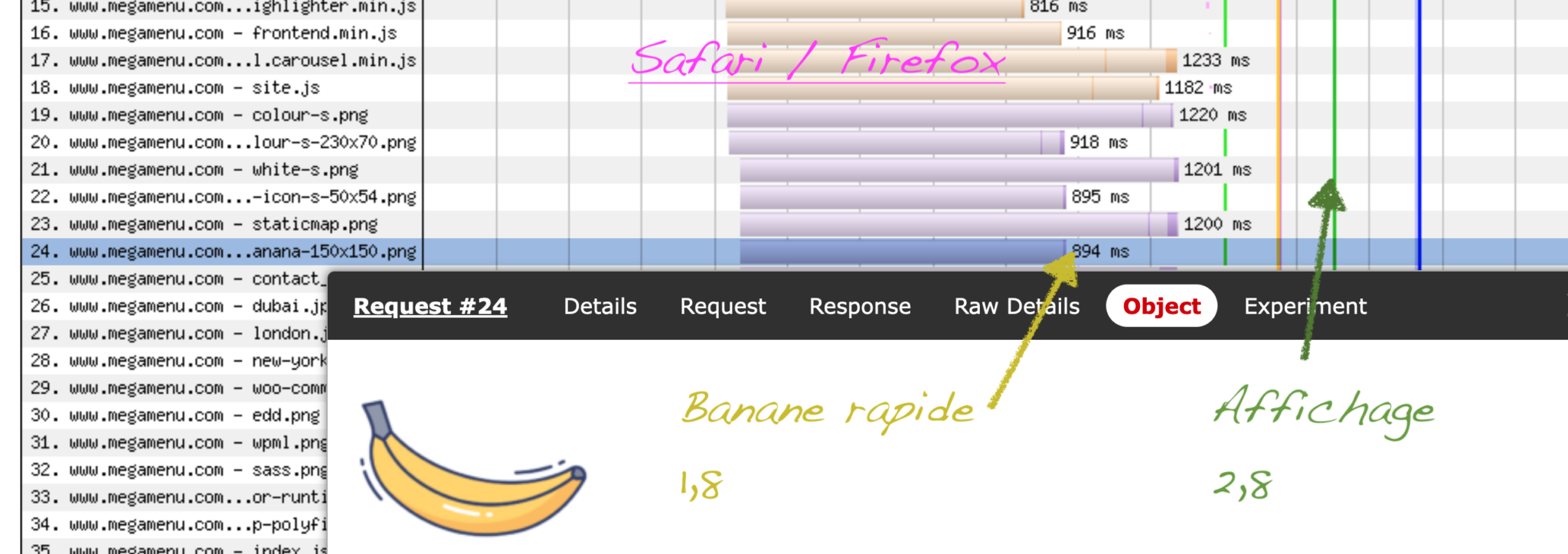
Bonne nouvelle, Chromium gère plutôt bien les images cachées. Comprenez qu’elles sont toujours chargées, donc que vous gaspillez tout autant de la bande passante, mais qu’elles ont une priorité basse lorsqu’elles sont ne sont pas visibles.
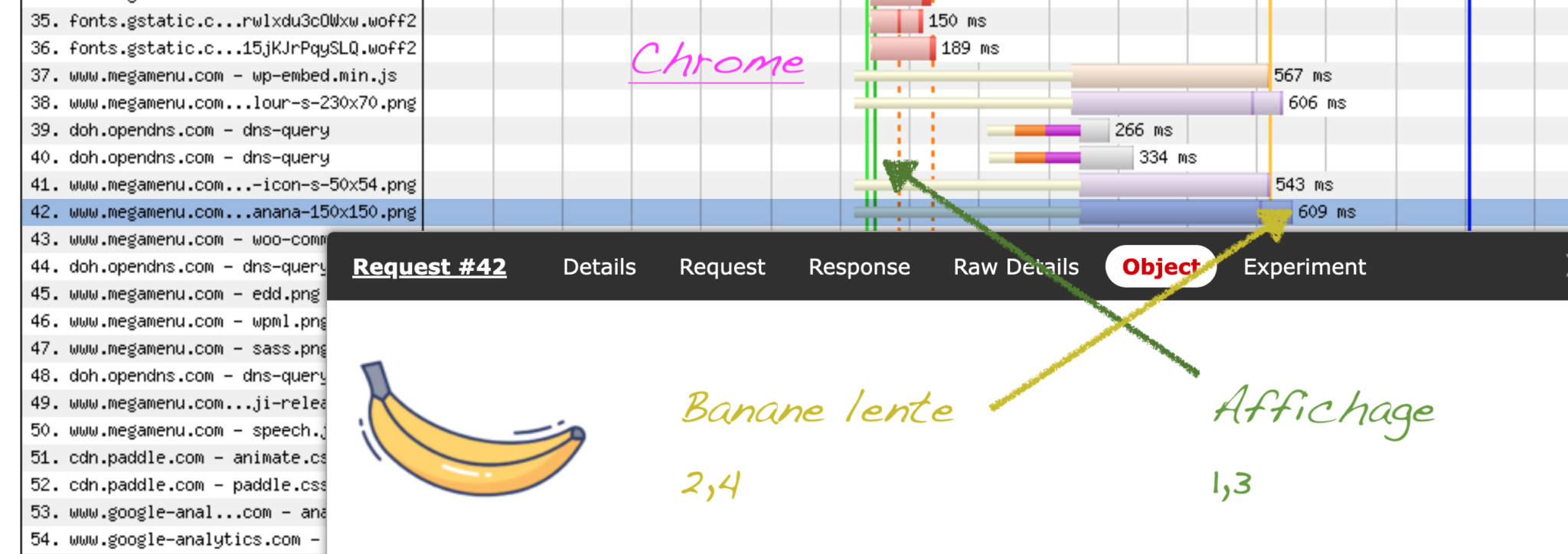
Chromium, c’est génial car il fait le boulot pour vous ? Regardez bien les trames réseau et vous allez vite comprendre que cela n’est pas neutre visuellement. Il y a une période d’attente sur toutes les images (IDLE, en blanc sur le screenshot ci-dessus). Chromium s’est bien noté qu’il chargera l’image mais pour connaître leur visibilité à l’écran il a besoin d’un DOM et d’un arbre CSS complet. Ce sont donc toutes les images qui démarreront tardivement, y compris celles qui sont bien visibles au milieu de l’écran. On y reviendra, car la correction n’est pas neutre.
Le lazy loading natif pourrait marcher mais dans le cas d’image cachée en CSS, il n’y a pour le moment que Chromium qui le fasse correctement (et c’est récent). Vous pouvez vérifier : dans ce même méga menu d’exemple, une image nommée contact_map.png est en lazy loading natif et seul Chromium ne la charge pas.
Viennent alors des questions mille fois entendues : parier sur les standards et un alignement du comportement des navigateurs ? Faire un peu de JS quitte à refaire le code plus tard ? Pourquoi une banane, fichtre ?
Cela dépendra du gain attendu (ici, la banane ne pèse que 8 Ko) et de l’effort de maintenance que vous comptez y mettre. Ça dépend™.
Une correction passe-partout, supposant que les images cachées là-haut sont décoratives et n’ont pas d’importance d’accessibilité ou en SEO serait de ne les charger que lorsque le menu est déplié. En bonus, la plupart des designs de méga menu sur mobile n’utilisent pas d’image par manque de place : c’est une bonne occasion de ne jamais les télécharger !
Que fait la police ?
La police, c’est frappant : il arrive encore de tomber sur un site avec du texte fantôme. Il est bien sûr dans le HTML, mais masqué aux yeux de l’utilisateur tant que le fichier de font qui s’y applique n’est pas chargé.
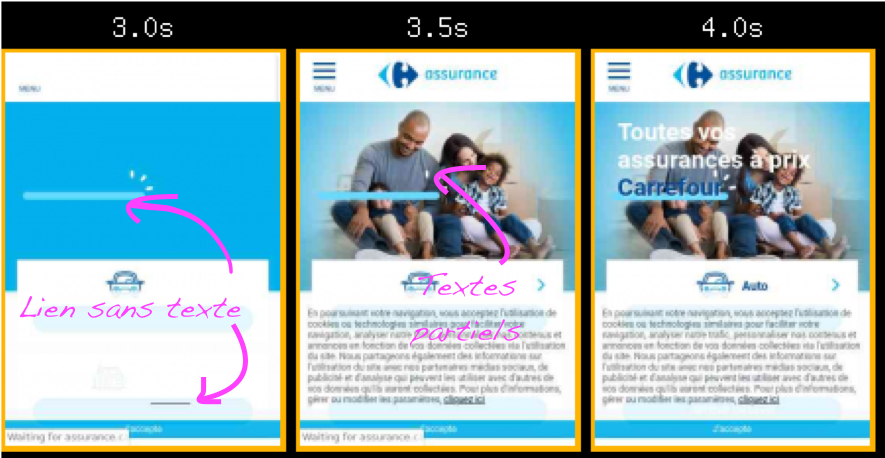
Pire, Safari a fait le choix de considérer une font comme un fichier aussi critique que le CSS : tant que les fichiers ne sont pas là, rien ne s’affiche.
Asynchrone et optimisations techniques
Pour résoudre le problème, et après avoir validé avec les gens responsables de l’expérience utilisateur que lire le texte au plus tôt c’est mieux, on va utiliser dans la déclaration @font-face une des valeurs de font-display : généralement c’est swap. La déclaration idéale ressemble à ceci :
@font-face {
font-family: 'Police';
font-weight: normal;
font-style: normal;
src:local('Police Name Regular'), /* Windows */
local('PoliceName-Regular'), /* MacOS */
url('police.woff2') format('woff2'),
url('police.woff') format('woff'); /* IE 11 */
font-display: swap;
unicode-range(U+0020-U+007E, U+00A0-U+00FF, U+20AC); /* Latin 1 supplement, € */
}
…
.element { font-family: 'Police', Arial ; }On a appliqué d’autres optimisations en passant :
- Le nom local de la police : si par chance elle est déjà installée sur la machine, il n’y aura rien à télécharger ! Microsoft et Apple ne sont pas accordés sur les règles de nommage. Aucune idée de ce qu’il se passe côté mobiles. 😕
- Utiliser un format compressé pour la police : WOFF 2. WOFF 1 n’est là que pour IE 9 à 11 et Android 4. L’ordre de déclaration compte, référencez d’abord la plus légère !
- On a découpé le fichier de font par grande famille de langue. Ici la valeur unicode-range correspond à Latin de base + Latin étendu – 1 + le signe €, soit un peu moins de 200 caractères.
J’utilise Warkamai Fondue pour vérifier le contenu des fichiers, Font Subsetter pour les découper avant de les convertir en WOFF 2 avec Font Squirrel Generator. Un fichier WOFF 2 avec moins de 200 glyphes doit se situer entre 15 et 25 Ko.
Bien entendu vous êtes du côté de la Loi et vous avez vérifié avant que le contrat avec le fondeur vous autorise à modifier le contenu à des fins d’optimisation. C’est le cas de la Roboto, sous licence Apache 2.0.
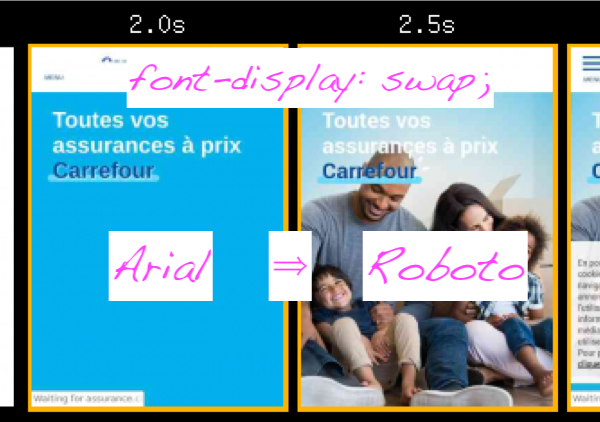
Le texte s’affiche plus vite sur tous les navigateurs et Safari affiche la page sans attendre. Mais on peut avoir fait apparaître un autre problème.
Corriger la police de repli
Ci-dessus la différence entre l’Arial et la Roboto est ténue mais cela ne sera pas le cas pour tous les designs et c’est encore un autre super-pouvoir de l’intégrateur que nous allons devoir activer. Exemple sur le site de la MAIF, dont l’identité visuelle utilise une police spécialement créée.
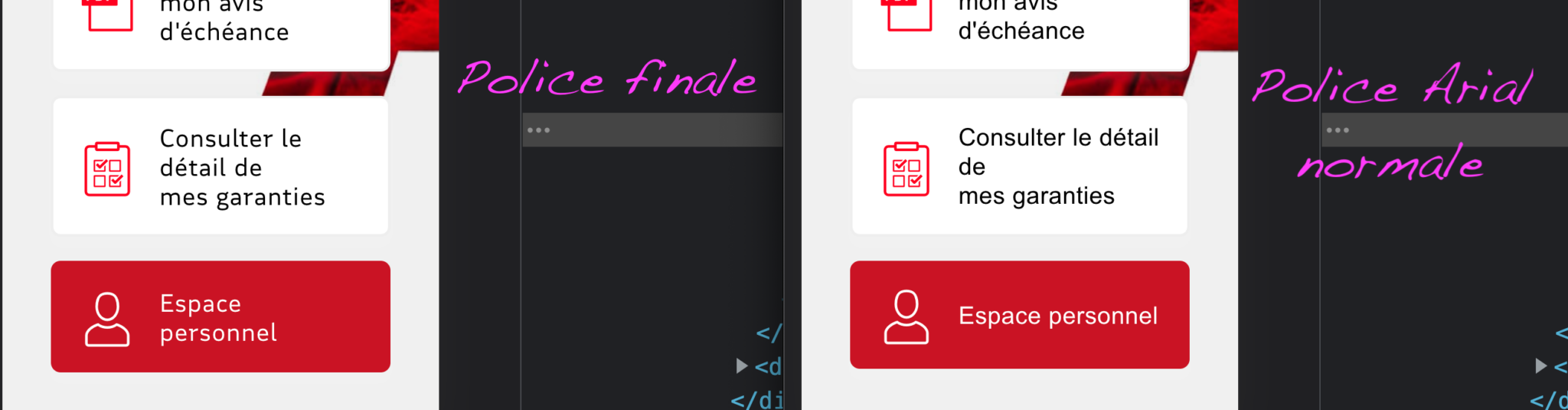
Le texte est lisible plus tôt mais on se retrouve ici avec des lignes en plus ou en moins qui vont faire sauter le texte et pousser les blocs sous les yeux de l’utilisateur à l’application de la font finale. Ça peut être perturbant et Google Search va même prendre en compte dans le classement une métrique mesurant cet effet : le Cumulative Layout Shift.
On peut corriger – et en pur CSS s’il vous plaît – les dimensions des polices de repli. Chromium a enfin suivi le pas de Gecko et Webkit en supportant la propriété CSS font-size-adjust. Elle permet, sans toucher à la font-size du texte, donc sans trafiquer les styles en JS, de modifier la taille d’une police.
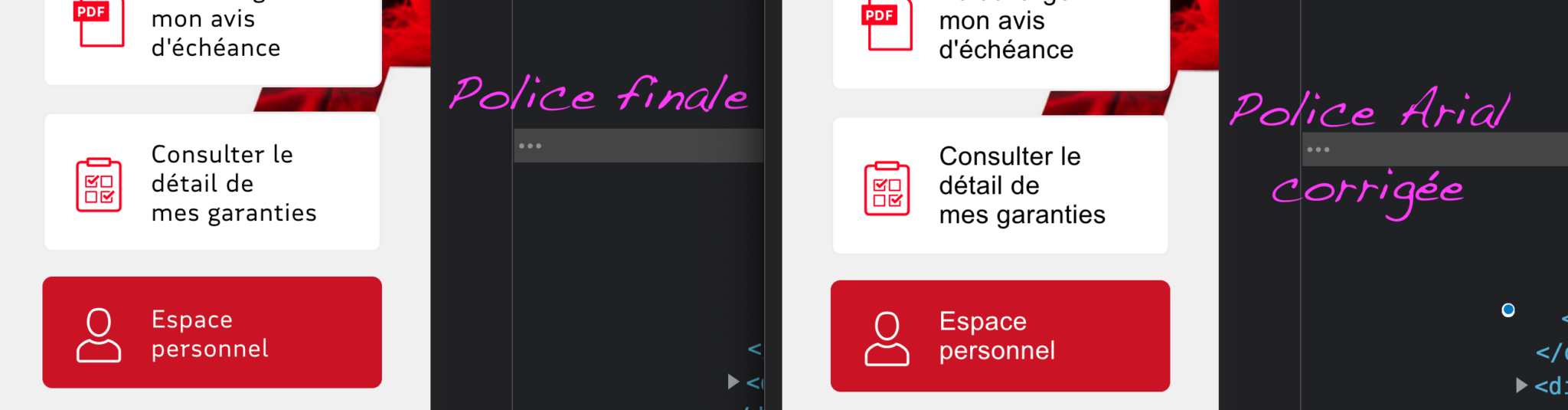
L’astuce est de partir d’une font dont on est à peu près sur qu’elle est installée sur la machine de l’utilisateur. Une lecture rapide de CSS Font Stack laisse peu de place à la créativité : repartons d’Arial, trouvons son nom dans les systèmes Mac et Windows (Arial…) et enfin cherchons le coefficient multiplicateur à mettre en valeur de size-adjust. Cette recherche se fait en tâtonnant, directement dans le navigateur.
@font-face {
font-family: ArialReplace;
src: local("Arial");
font-display: swap;
font-weight: 400;
font-style: normal;
size-adjust: 106.8%
}
…
.element { font-family: 'Police', 'ArialReplace', sans-serif; }Cette correction est en production sur le site de maif.fr et a permis au domaine entier d’avoir un CLS à 0 pour 99 % des utilisateurs d’après les chiffres de la police Google.
Conclusion
L’intégration est responsable d’une bonne partie des optimisations possibles en performance d’affichage. Les techniques ne sont pas moins complexes que la configuration d’un cache back-end, d’optimiser une base de données ou de comprendre le cycle de vie d’un composant React.
Je termine avec un conseil que je donne lors de mes discussions post-audit avec les CTO, CDP ou les tech leads : si l’équipe n’est constituée que de devs, il faut au moins un spécialiste du HTML et du CSS pour améliorer la qualité globale du produit. C’est vrai pour la performance mais aussi l’accessibilité, la relation avec le design, la compréhension de l’expérience utilisateur et même la maintenance de code.
7 commentaires sur cet article
Nicolas Lœuillet, le 6 décembre 2021 à 8:48
Très instructif, même pour des non intégrateurs :) (et merci pour les jeux de mots)
Stéphane Deschamps, le 6 décembre 2021 à 9:00
Excellent article, grand merci.
(voilà, je n'ai rien de plus à dire, mais j'ai beaucoup appris alors je dis merci, et je me suis régalé de ton style, ce qui n'est pas non plus négligeable )
Boris, le 6 décembre 2021 à 9:07
Un excellent article, plein de petits rappels bien utiles tant on oublie parfois des optimisations assez simplement à portée. Merci !
Gaël Poupard, le 6 décembre 2021 à 9:34
Merci, encore des choses à tester et découvrir !
Nico, le 6 décembre 2021 à 14:52
> si l’équipe n’est constituée que de devs, il faut au moins un spécialiste du HTML et du CSS pour améliorer la qualité globale du produit.
C'est mon rôle là où je suis, et on constate que le bon dev ratio est 1 pour 4 (à ajuster selon les besoins bien sûr).
1 expert HTML/CSS pour 4 experts JS. Sinon ces derniers se vautrent systématiquement parce que c'est pas leur métier de lutter non pas contre, mais AVEC le navigateur:
Enfin bon, c'est pas un peu comme si on le disait depuis des ANNÉES.
Maïa, le 6 décembre 2021 à 18:17
Un article comme j'aurais aimé en lire plus tôt ! Merci à toi, c'était très instructif
Eroan Boyer, le 18 décembre 2021 à 16:40
Bravo pour ce tour d'horizon à la fois pédagogique et technique ! C'est clairement à jour côté conseils, ce qui est plutôt rare dans les articles qui traitent à la fois des JS, CSS, images et fontes.
Il n’est plus possible de laisser un commentaire sur les articles mais la discussion continue :