Dans les coulisses de la vidéo
Regarder un live stream sur Twitch, votre série du moment sur Netflix, ou une vidéo intégrée à un site Web apparait aujourd’hui comme anodin. Mais en coulisses, de l’édition à la diffusion, les traitements se suivent et ne se ressemblent pas ! Sortons un instant du code qui fait notre Web, pour parler pixels, couleurs ou encore codecs ! Une introduction à l’univers de la vidéo dans lequel je baigne depuis bientôt trois ans chez Pitchy.
Qu’est ce qui compose une vidéo ?
Commençons par la terminologie, histoire de bien s’entendre. Ce qu’on entend par « vidéo » sur le Web va bien au delà de quelques images. C’est avant tout un conteneur. MP4 (Moving Picture Experts Group 4), MKV (Matroska Video) font partie des conteneurs les plus répandus. Comme son nom l’indique, c’est un réceptacle, destiné à accueillir des flux de données (streams).
Des flux certes, mais pas n’importe lesquels, et pas n’importe comment. On trouve en général un flux vidéo, un flux audio et parfois des flux de sous-titres, compressés grâce à des codecs (nous aurons l’occasion d’y revenir plus tard). Chaque conteneur supporte son lot de codecs spécifiques.
Zoom sur le flux vidéo. Ce dernier est composé de frames, des images successives jouées à une certaine fréquence, appelée FPS (Frames Per Second). Plus le FPS est élevé, plus la vidéo est fluide. Chaque frame est un ensemble de pixels, et chaque pixel est défini par par une couleur, représentée dans un espace de couleur (RGB (Red Green Blue), YUV1 entre autres).
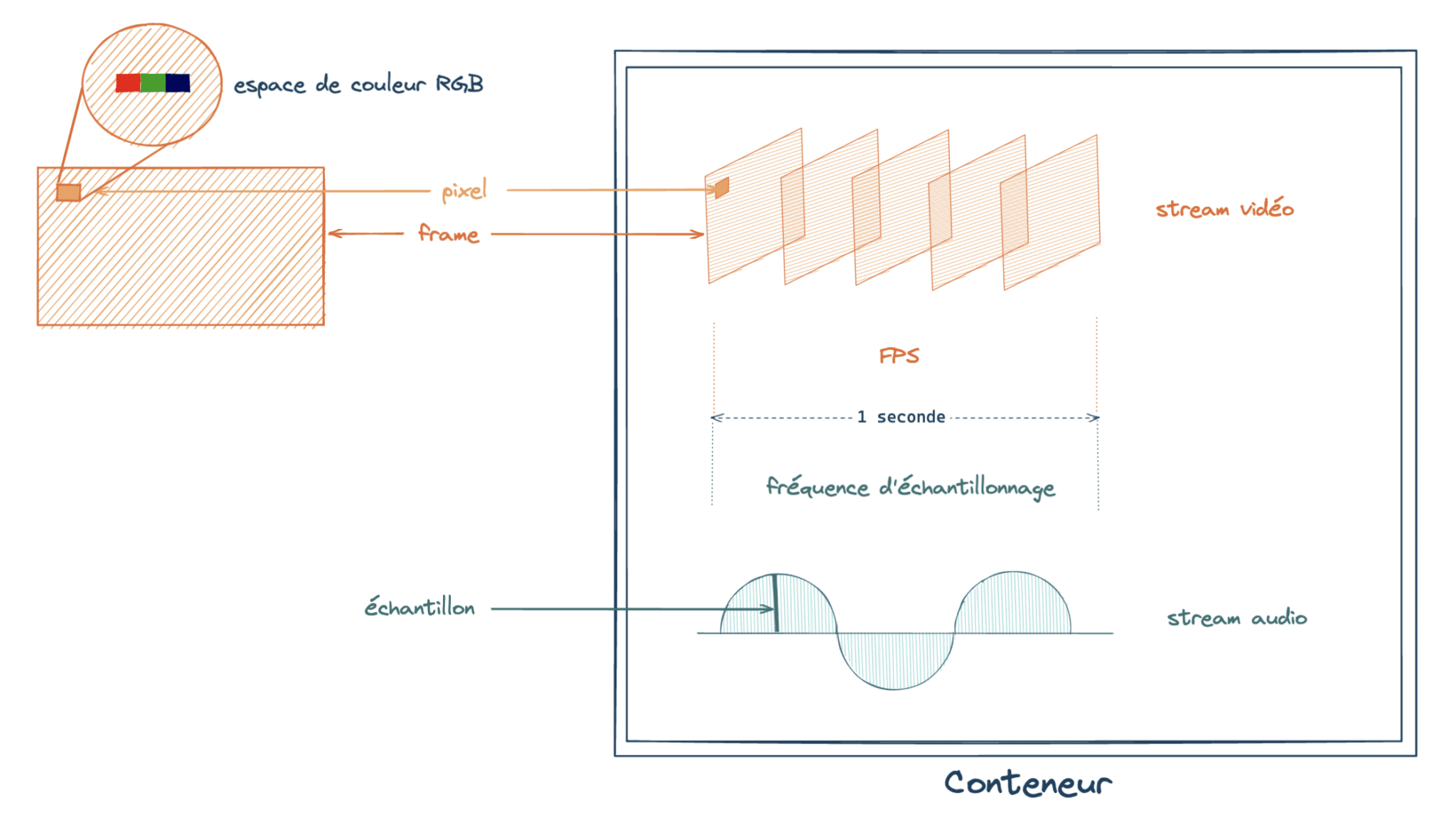
Après ces précisions, nous voilà fin prêts à nous lancer dans l’aventure !
Au commencement, l’édition vidéo
Avant de diffuser notre vidéo, encore faut-il la produire ! De la captation à la post-production, un seul mantra : qualité et efficacité.
Le premier objectif est une captation avec des couleurs les plus fidèles possibles, donc peu ou pas de compression pour conserver un maximum d’informations. Cette compression des couleurs est définie par la structure d’échantillonnage. Les appareils professionnels enregistrent avec une structure 4:4:4 (sans compression) ou 4:2:2 (compression minime).
Et l’efficacité dans tout ça ? Elle est nécessaire en post-production, où l’on navigue souvent d’une frame à l’autre de la vidéo. Chaque codec vidéo a sa propre méthode de compression, et certaines peuvent considérablement ralentir les allers-retours entre différentes frames.
Il existe deux familles de codecs :
- les codecs inter-frame, qui se basent sur un algorithme de compression temporelle : on compresse les informations d’une frame par rapport aux frames voisines,
- les codecs intra-frame, qui se basent sur un algorithme de compression spatiale : on compresse les informations d’une frame individuellement, en approximant entre eux les blocs de pixels qui la composent.
Pour l’édition, on privilégie les codecs intra-frame (comme ProRes), car chaque frame est auto-suffisante et peut être décompressée sans avoir à chercher d’autres frames. Plus rapide, mais au prix d’une compression bien moins efficace.
Vous l’aurez donc compris, la qualité et l’efficacité se font au détriment… de la taille.
La diffusion, ou comment optimiser sa vidéo pour le Web
Changement de paradigme ici. Bien que l’on cherche à maximiser la qualité de la vidéo, on doit faire face à deux contraintes :
- Pouvoir lire des vidéos avec une bande passante inégale et parfois faible,
- Pouvoir stocker des vidéos sans dépenser des millions.
Un problème de taille donc. Mais pas de panique, on peut faire d’excellents compromis en ayant une influence minimale sur la qualité perçue, grâce au tiercé gagnant H264, Sous-échantillonnage chromatique, DASH (Dynamic Adaptive Streaming over HTTP).
Le codec H264
Revenons sur la notion de codec. Ce mot est la contraction de coder et décoder. Autrement dit, c’est un algorithme capable de compresser de l’information vidéo pour la stocker, puis de la décompresser pour la rendre lisible dans un lecteur.
Une minute de vidéo non compressée, en Full HD (Haute Définition), à 25 FPS, pèse près de 9 Go (gigaoctet). Une fois passée dans la moulinette H264, elle ne pèse plus que 600 Mo (mégaoctet) environ3. Ce tour de force est possible car H264 est un codec inter-frame.
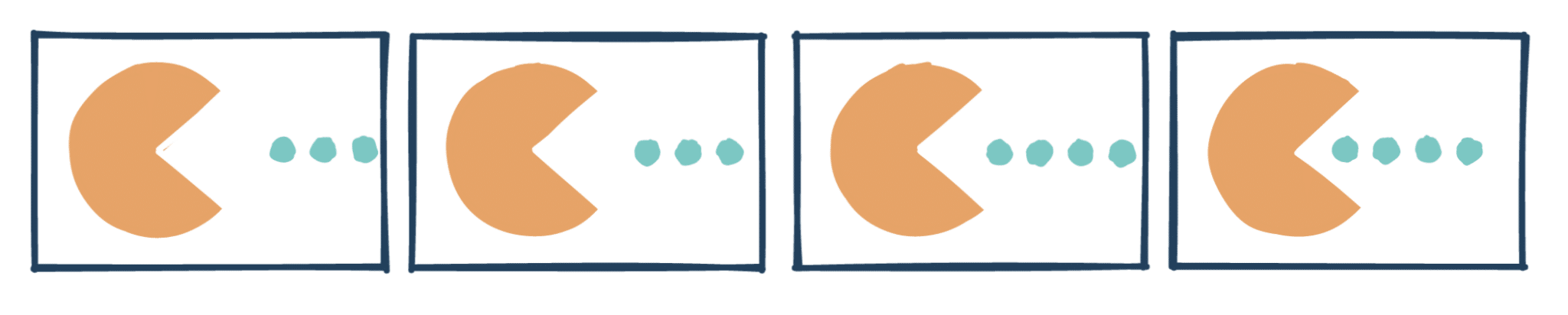
Imaginons un flux vidéo non compressé, composé des frames ci-dessus. Chaque frame comporte toute l’information permettant de la décrire.
On constate que d’une frame à l’autre, il y a beaucoup de zones « statiques », qui ne changent pas ou très peu, et c’est là qu’est le cœur de l’optimisation : plutôt que de stocker toute l’information de ces pixels, on va simplement stocker leur « vecteur de déplacement » par rapport à une autre frame.
H264 va décomposer le flux en trois types de frames :
- les I-frames, des frames complètes,
- les P-frames ou Predicted frames, estimées à partir de I-frames ou P-frames précédentes,
- les B-frames ou Bidirectional frames, estimées à partir de frames précédentes et/ou suivantes.
Optimisé de la sorte, notre flux vidéo pourrait être décrit ainsi :
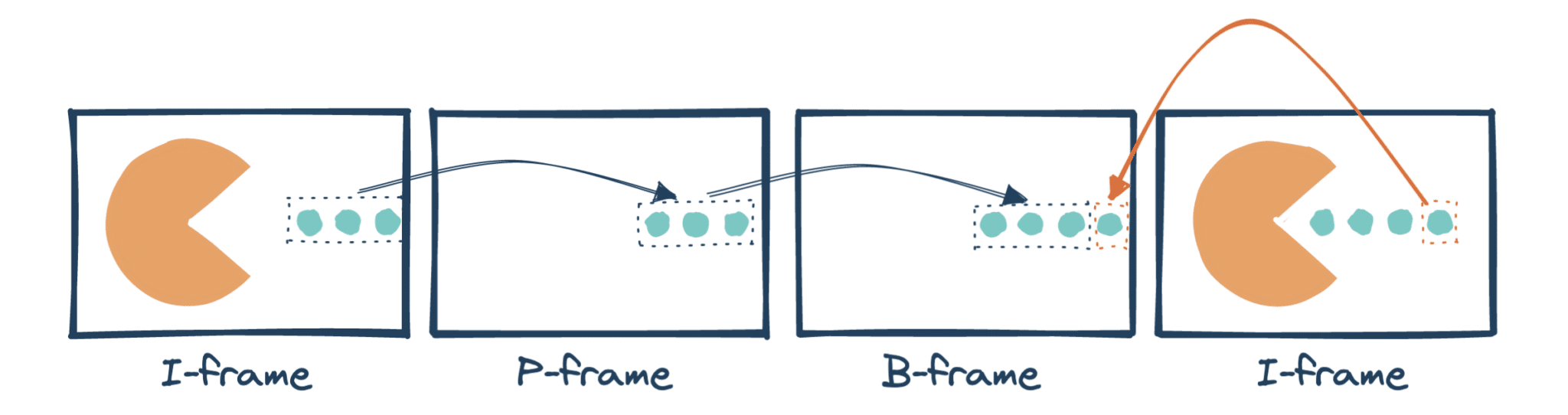
Cette compression est bien plus efficace, car il est plus facile de trouver des ressemblances entre des frames adjacentes qu’entre des blocs de pixels voisins, comme le fait un codec intra-frame. Mais il nous reste un problème : le fonctionnement des B-frames. Comment se reposer sur une frame postérieure, qui n’est pas encore « apparue » ? Grâce à la notion de PTS/DTS.
Chaque frames possède deux timestamps :
- le PTS, ou Presentation Time Stamp, qui décrit quand la frame doit être jouée,
- le DTS, ou Decoding Time Stamp, qui décrit quand la frame doit être décodée.
Ainsi, une frame bi-directionnelle aura un DTS supérieur aux frames dont elle dépend, bien qu’elle apparaisse avant. Dans notre exemple, ça donne :
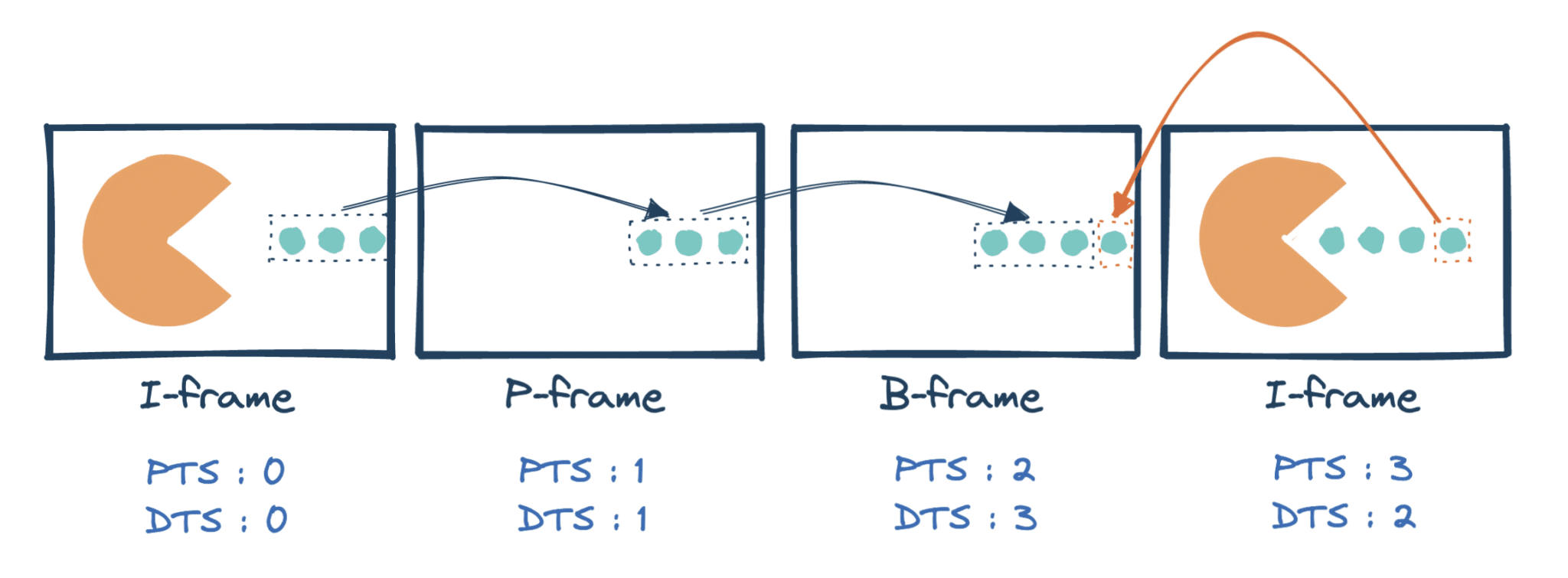
Maintenant que nous avons réduit le nombre de pixels nécessaires pour décrire la vidéo, il est temps de compresser les couleurs !
Le sous-échantillonnage chromatique, de 4:4:4 à 4:2:0
Derrière ce terme un peu barbare, et ces notations un peu cryptiques, se cache la même idée : réduire le nombre de composantes utilisées pour décrire la couleur d’un pixel.
Commençons par un peu d’histoire autour de l’espace de couleurs YUV. À l’époque de la télévision en noir et blanc, un pixel était décrit par une information de luminance (comprenez par là, un niveau de gris). Arrive la télévision en couleurs, et la nécessité de diffuser un signal vidéo qui soit rétrocompatible avec les anciens postes monochromes ! Exit RGB, qui aurait besoin des trois composantes pour décrire un gris. On décide d’ajouter deux composantes de chrominance, U et V, pour décrire la couleur.
Remarque
Historiquement, YUV, ou plus précisément Y’UV (Y” = Y avec une correction gamma) est utilisé dans le cadre d’un signal analogique. Aujourd’hui, on parle de YCbCr2 pour un signal numérique, plus précisément Y’CbCr. La plupart du temps, YUV reste le nom donné à l’espace de couleur par abus de langage.
Bien que la télé en noir et blanc soit loin derrière nous, YCbCr reste très utile pour du sous-échantillonnage chromatique. L’œil humain est beaucoup plus sensible à la composante de luminance qu’aux composantes de chrominance. Par conséquent, on peut faire des coupes significatives sur ces dernières, sans percevoir la moindre différence sur le résultat.
Revenons à nos structures d’échantillonnage, et prenons un bloc de 4×2 pixels, chacun décrit par ses trois composantes, ici Y, Cb et Cr. Une structure d’échantillonnage décrit quelles composantes seront gardées dans ce bloc, sous la forme x:y:z, où :
- x représente le nombre de composantes Y par ligne,
- y représente le nombre de composantes Cb-Cr sur la première ligne,
- z représente le nombre de composantes Cb-Cr sur la deuxième ligne.
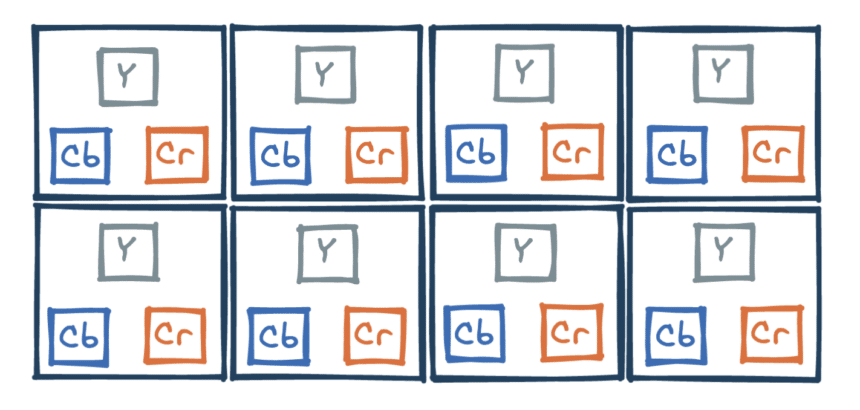
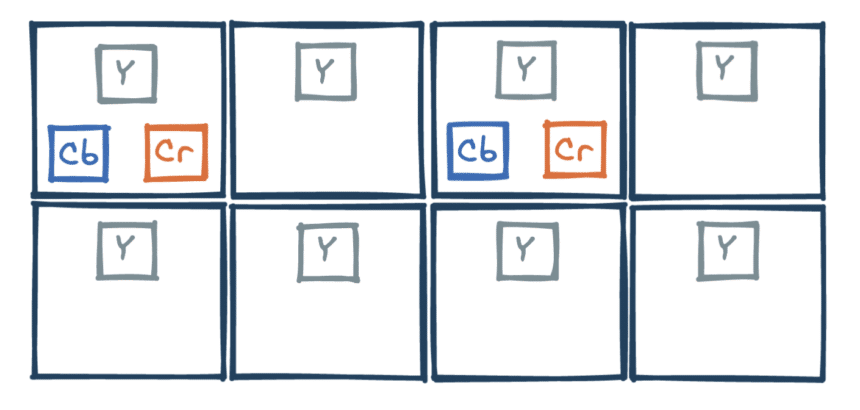
Ainsi, YUV 4:4:4 décrit une structure d’échantillonnage sans compression, où chaque composante est gardée (24 en tout).
Le plus important reste les composantes Y, porteuses de la majorité de l’information, qui ont tout intérêt à être intégralement conservées. C’est pourquoi les structures 4:x:x sont les plus populaires. Un excellent compromis entre qualité et compression est la structure 4:2:0, qui divise par deux le nombre de composantes gardées !

Notre vidéo est maintenant optimisée en taille pour occuper un espace de stockage réduit. Il reste un paramètre sur lequel on peut intervenir : la résolution, ou le nombre de pixels par frame. Avec l’explosion du streaming vidéo, il devient nécessaire d’optimiser le flux de données pour garantir l’expérience la plus fluide. C’est ici qu’intervient notre troisième tour : DASH.
DASH, la magie derrière la résolution adaptative
DASH est un standard de diffusion. L’objectif est simple : avoir à chaque instant des données vidéos dans la mémoire tampon, prêtes à être jouées, peu importe la bande passante disponible.
- Diviser la vidéo en plusieurs segments (entre 2 et 10 secondes),
- Encoder les flux de chaque segment avec différentes combinaisons de codecs, résolutions, bitrates (nombre de kb (kilobytes) par secondes),
- Servir le segment « le mieux adapté » à la situation.
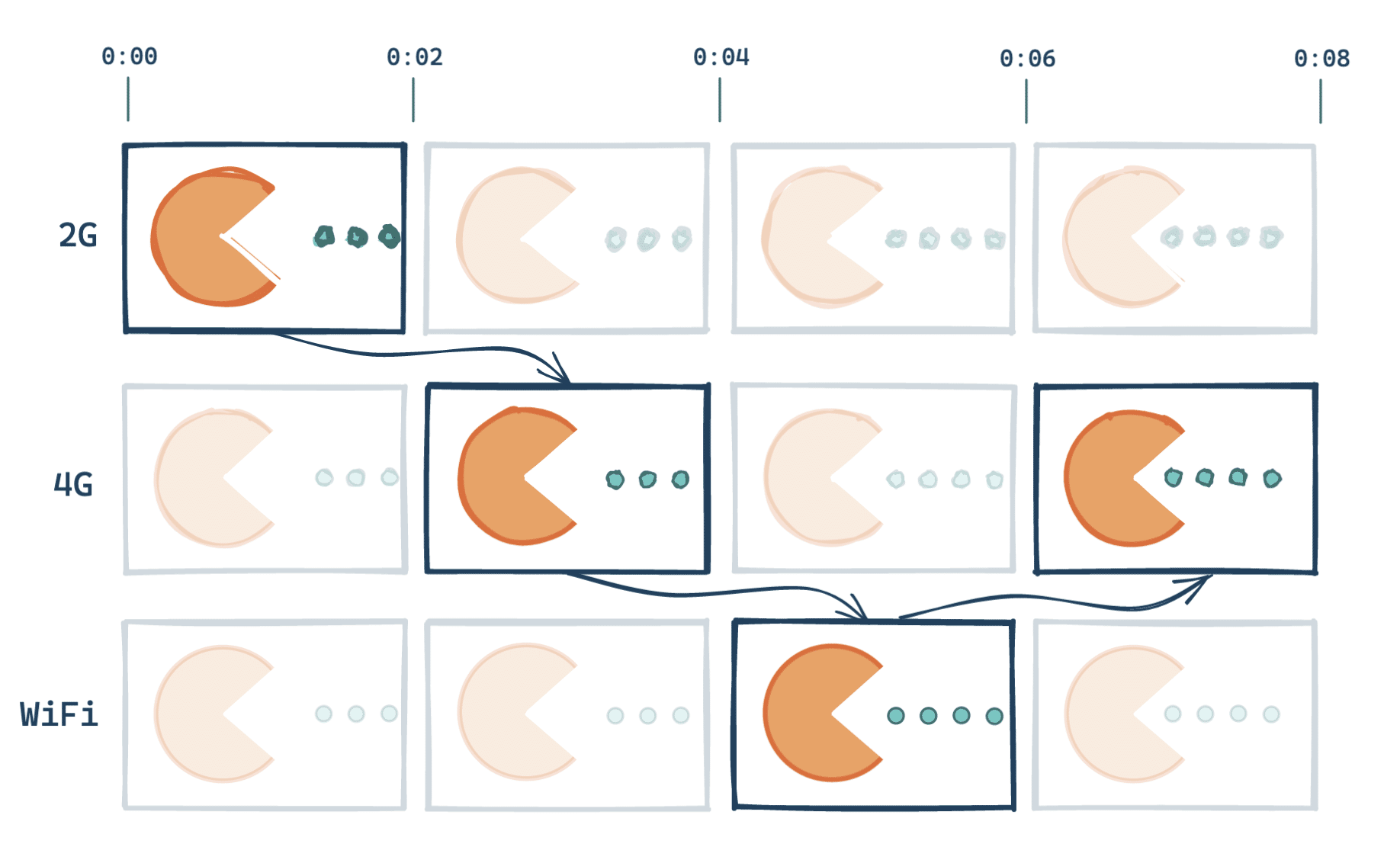
Plusieurs facteurs sont à prendre en compte pour déterminer le meilleur segment :
- la quantité de bande passante disponible, afin de déterminer notre vitesse de téléchargement,
- la stabilité de la bande passante (éviter de changer constamment de résolution si elle est en dents de scie),
- la quantité de flux vidéo disponible dans la mémoire tampon — si on consomme plus vite qu’on ne télécharge, il serait peut-être temps de baisser la résolution,
- les propriétés de l’appareil sur lequel est joué la vidéo — même avec la fibre, inutile de télécharger une vidéo 4K sur un petit écran de smartphone !
- les préférences utilisateurs : choix d’une résolution, d’une langue audio.
L’ensemble des segments disponibles est décrit dans un fichier MPD (Media Presentation Description), aussi appelé DASH Manifest. Ce fichier au format XML (eXtensible Markup Language) est décomposé de la façon suivante4 :
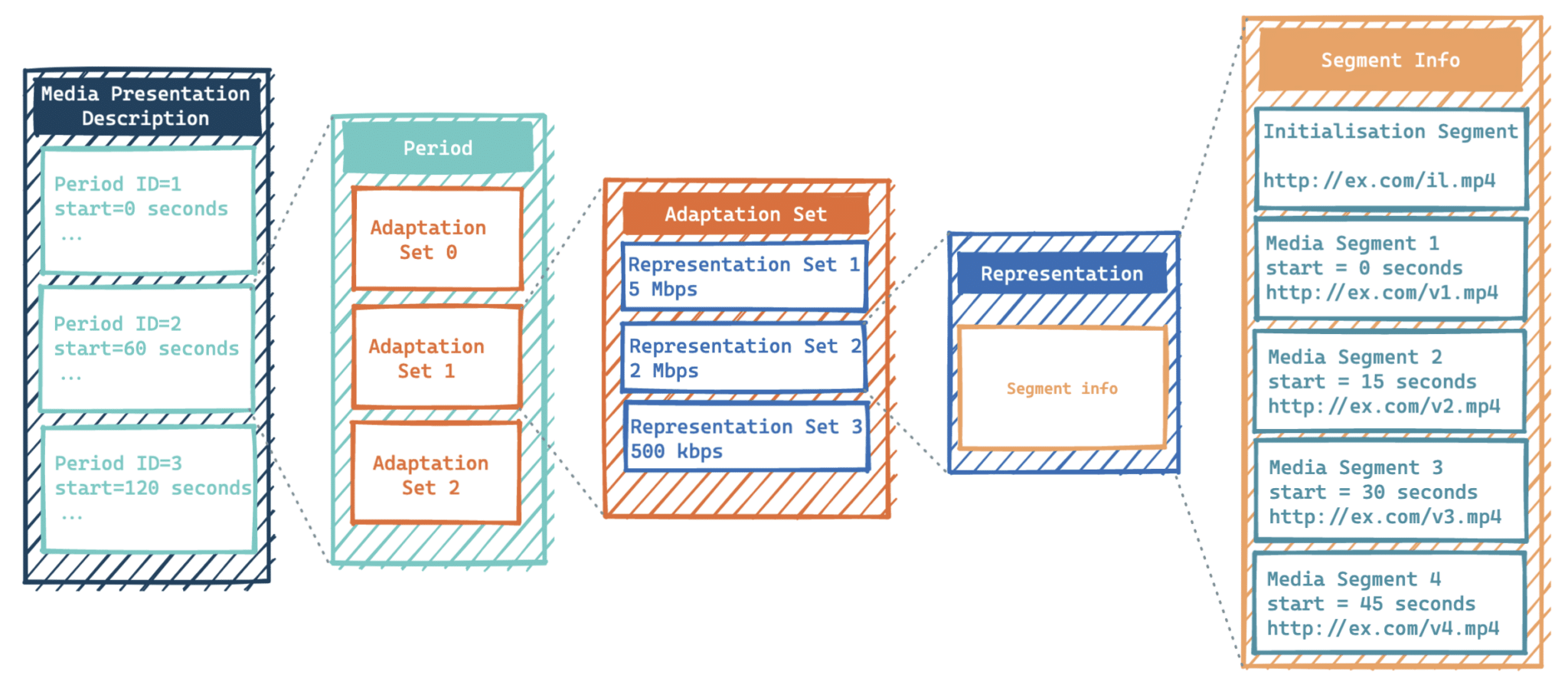
Au sommet du fichier, on trouve des informations globales comme la durée maximale d’un segment, ou la durée minimale d’un buffer (combien de secondes de vidéo doivent être idéalement présentes dans la mémoire tampon).
Le fichier vidéo est découpé en plusieurs tronçons consécutifs (appelés périodes) ce qui permet notamment de gérer une notion de chapitrage — et l’insertion de coupures publicitaires !
Chaque période possède plusieurs Adaptation Sets. Ce sont des catalogues répertoriant les différentes versions de chaque flux :
- pour la vidéo, il y a un catalogue par codec utilisé ;
- pour l’audio, il y a un catalogue par format de diffusion (stéréo, surround, etc), mais aussi un par langue si besoin.
Chaque catalogue comporte plusieurs Representation Sets. Ces derniers décrivent différentes versions du contenu, notamment quelle résolution afficher en fonction de la bande passante.
Enfin, chaque Representation Set comporte des Segments, qui pointent vers les URLs (Uniform Resource Locator) permettant de télécharger le contenu.
Et dans le futur ?
La nouvelle génération de codecs — AV1 et HEVC (High Efficiency Video Coding, également appelé H.265) — est déjà dans les tuyaux. Plus performants, ils permettent d’envisager la diffusion de vidéo de plus haute résolution (hello la 8K) sans monopoliser la bande passante. Néanmoins, leur adoption reste conditionnée par la compatibilité hardware. Côté distributeurs, Netflix diffuse déjà certaines de ses vidéos en AV1 depuis 2021, mais seuls des modèles récents de téléviseurs le supportent nativement. Pour le reste, il faut passer par un décodeur externe (via une PlayStation 4 Pro par exemple). Qualcomm projette de supporter AV1 dans sa nouvelle génération de processeurs, prévue pour 2023. Enfin, Google met également la pression aux constructeurs, en imposant le support AV1 pour pouvoir accueillir Android 14.
- ↑ NDLR (Note de la rédaction) : YUV n’est pas un acronyme mais plutôt une formule, chaque lettre représentant une composante du modèle colorimétrique. YUV sur Wikipédia.
- ↑ NDLR : comme pour YUV, il s’agit d’une formule. YCbCr sur Wikipédia.
- ↑ Ceci est une estimation, car la taille exacte peut varier selon le bitrate (nombre de bits traités par unité de temps, exprimé généralement en kbps, ou kilobits par seconde). Une vidéo assez « statique », comme un plan fixe d’une personne parlant devant un mur, aura un bitrate bien plus faible qu’une vidéo d’un skieur faisant du hors piste à toute allure !
- ↑ Structure of an MPEG-DASH MPD.
2 commentaires sur cet article
Dandu, le 18 décembre 2022 à 12:36
C'est super intéressant, mais il y a un souci de chiffres à un moment : parce que 600 Mo/minute en H.264 pour du Full HD, c'est vraiment super large : c'est un débit de 80 Mb/s.
Une compression moyenne, c'est genre facilement 10x moins (et sur YouTube et autres, on est vers 20x moins).
Sonia Seddiki, le 19 décembre 2022 à 15:33
Merci pour le retour :) !
N'ayant pas de vidéo non compressée sous la main, je me suis basée sur un calculateur en ligne pour avoir une source commune pour les deux calculs. J'ai surtout regardé la différence d'ordre de grandeur, et avec le recul, c'est vrai que la valeur en elle même est un peu large.
Je ne sais pas sur quels paramètres se base le site pour effectuer ses calculs, il propose d'ailleurs différentes "versions" de H.264 1080, et toutes retournent un résultat différent.
Il n’est plus possible de laisser un commentaire sur les articles mais la discussion continue :