Des tableaux de données complexes accessibles, c’est possible ?
Introduction
Les tableaux existent depuis que le web est web… Même si à l’époque nous les avons surtout utilisés pour disposer librement le contenu de nos pages1
(qui se souvient d’Image Ready2
?… OK, je suis vieux). Aujourd’hui, la plupart des personnes qui développent ont abandonné ces usages3
et ne ressortent la balise <table> que pour intégrer des tableaux de données.
Mais alors, pourquoi produisons-nous encore aujourd’hui des tableaux inaccessibles ?
J'ai identifié deux raisons :
- un souci de culture numérique ;
- des limitations techniques.
Un souci de culture numérique
Beaucoup de personnes font encore la confusion entre structurer de l’information dans un tableau de données et présenter cette information dans un damier ressemblant (vaguement) à un tableau. Il suffit d’ouvrir quelques fichiers Excel partagés entre collègues pour s’en rendre compte (sauf si tou·tes vos collègues maîtrisent VBA et les tableaux croisés dynamiques).
De plus, toutes les personnes intégrant des tableaux sur le web ne sont pas des expertes du HTML/CSS, et sont encore moins expertes en accessibilité. De nombreuses personnes qui utilisent des CMS produisent des tableaux sans entrer une ligne de code (si c’est votre cas, ne partez pas ! Je me suis efforcé de rester sur les concepts et de mettre le moins de code possible).
Au cas où, je préciserai donc que nous nous intéressons ici aux tableaux de données :
- ces tableaux présentent l’information de manière structurée ;
- cette structuration est obtenue en plaçant des cellules d’en-têtes qui vont nous informer sur le sens des autres cellules.
Des limitations techniques
Même en intégrant nos tableaux avec une structure correcte de l’information et en respectant à la lettre la documentation MDN, nous pouvons nous heurter aux limites de la machine :
- certaines combinaisons de navigateurs d’écran et lecteurs d’écran provoquent d’étranges anomalies de restitution ;
- certaines structures semblent être tout simplement trop complexes pour les lecteurs d’écran (à moins que ce ne soit les navigateurs qui échouent à construire un accessibility tree cohérent ? Peut-être un peu des deux).
C’est en lisant la rubrique « tables » du blog d’Adrian Roselli que j’ai découvert l’étendue du problème. Dans ses articles, Adrian explore des cas extrêmes, poussant navigateurs et lecteurs d’écrans dans leurs retranchements et mettant en avant des anomalies de restitution assez problématiques. J’ai poursuivi mes lectures jusqu’à avoir une bonne idée de ce qui ne marche pas (ou du moins ne marchait pas4 ) mais il me restait difficile de définir quels tableaux sont véritablement accessibles en 2025.
Je me suis donc retroussé les manches pour entreprendre une synthèse des connaissances sur le sujet et vous présenter différents motifs5 de tableaux pouvant être utilisés « les yeux fermés ». J’évoquerais aussi quelques motifs à éviter (et des conseils pour les restructurer afin d’obtenir des tableaux plus accessibles).
Remarque : les problématiques évoquées dans cet article concernent essentiellement les critères sur la structuration de l’information6
mais les tableaux peuvent impacter d’autres critères, notamment les critères 1.4.10 Redistribution (Reflow, en anglais) et 2.5.7 Mouvements de glissement. Pour éviter que les tableaux fournis en exemple de cet article ne provoquent des erreurs sur ces critères, je leur ai appliqué une petite technique pensée pour éviter que nos tableaux ne déforment nos pages sur les écrans étroits de nos smartphones.
Cette technique est décrite dans cet article de Steve Faulkner.
Si le sujet vous intéresse, cet autre article de Bogdan Cerovac se penche sur les impacts concrets de ces critères pour des utilisateurs et utilisatrices avec différents types de handicaps.
Les spécifications face à la réalité
Préambule : rappel rapide des spécifications
Je ne vous ferai pas un cours complet sur l’implémentation d’un tableau, d’autres ressources le font déjà très bien :
- Documentation MDN : Table accessibility
- Access42 : « Tableaux de données complexes : comment les intégrer de manière accessible en HTML ? », par Maïa Kopff
Ce qu’il faut retenir c’est que deux méthodes sont proposées pour renseigner les lecteurs d’écrans sur la structure d’un tableau (et comment la restituer à leurs utilisateurs et utilisatrices) :
- déclarer sur chaque en-tête son « périmètre d’action » (scope) ;
- associer les cellules une à une avec les différents en-têtes.
La méthode par « périmètre d’action » (scope) :
C’est la méthode la plus simple et la moins lourde à mettre en place. Avec cette méthode, on indique sur chaque en-tête d’un tableau si celle-ci concerne sa colonne, sa ligne, ou son groupe de colonnes ou de lignes (quand l’en-tête est une cellule fusionnée).
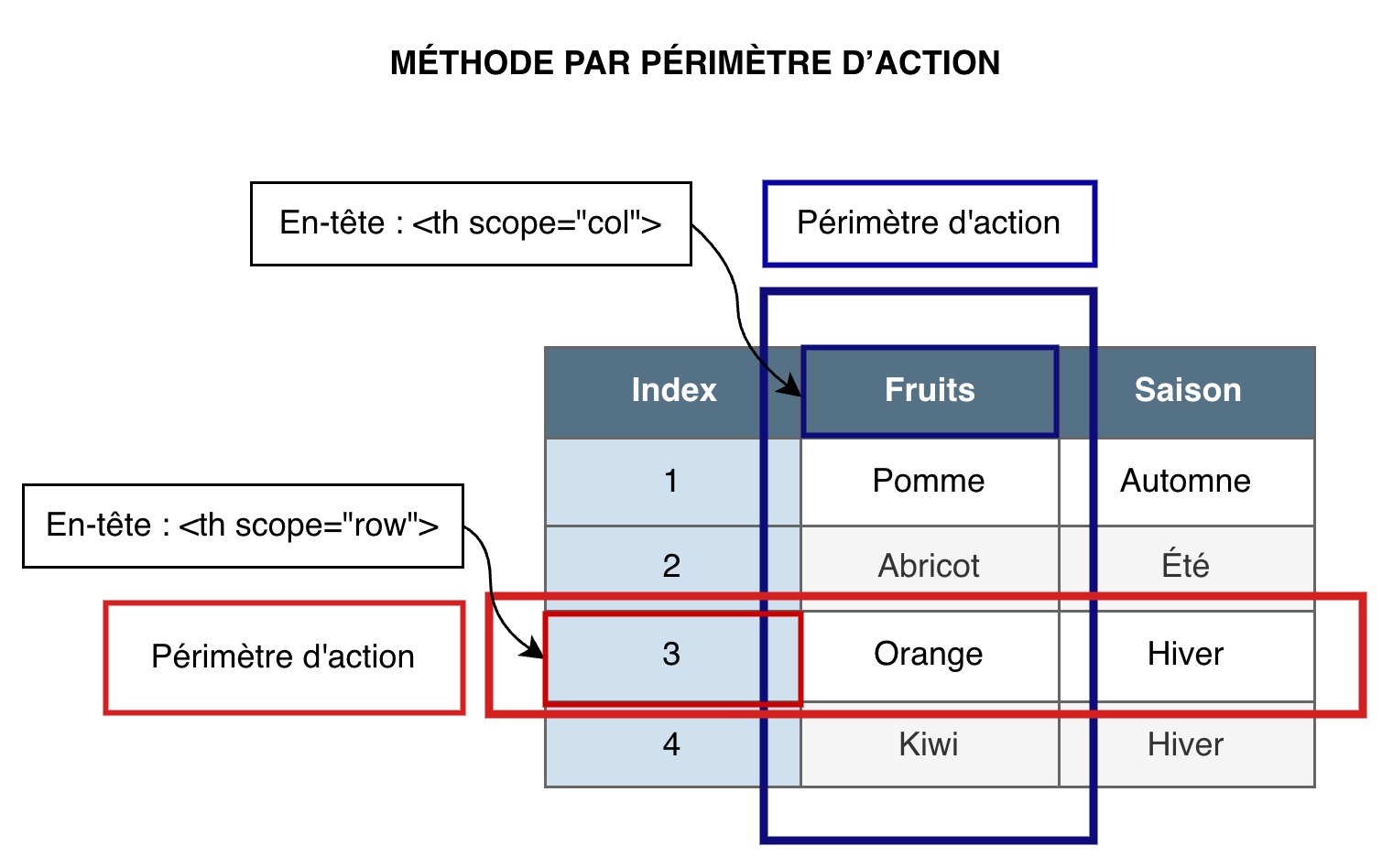
Description du schéma « Méthode par périmètre d’action »
Le tableau de trois colonnes et cinq lignes contient une liste de fruits et indique leur saison. La première colonne contient un index des fruits listés ; la deuxième colonne liste les fruits ; la troisième colonne montre la saison des fruits.
La première cellule de la deuxième colonne est nommée « Fruits » et le schéma précise que c’est un en-tête avec un attribut scope="col" qui veut dire que cet en-tête s’applique à toutes les cellules de cette colonne.
La quatrième cellule de la première colonne contient l’index « 3 » et le schéma précise que cette cellule est un en-tête avec un attribut scope="row" qui veut dire que cet en-tête s’applique à toutes les cellules de cette ligne.
Remarque : pour les tableaux les plus simples (pas de cellules fusionnées) et avec une structure « standard » de l’information7
, il n’est pas nécessaire d’apporter cette précision : sans instructions le navigateur déduira une structure par défaut à transmettre au lecteur d’écran.
À titre personnel, je préfère toujours expliciter la structure de mes tableaux, mais ce n’est pas une obligation, tant que la structure du tableau reste simple et conventionnelle.
La méthode par association manuelle des cellules
Cette méthode est plus versatile et peut s’appliquer aux tableaux les plus complexes. Elle s’applique en deux temps :
- on assigne un ID (identifiant) unique à chaque en-tête
- on ajoute à chaque cellule un attribut
headerslistant les ID de tous les en-têtes associées à cette cellule.
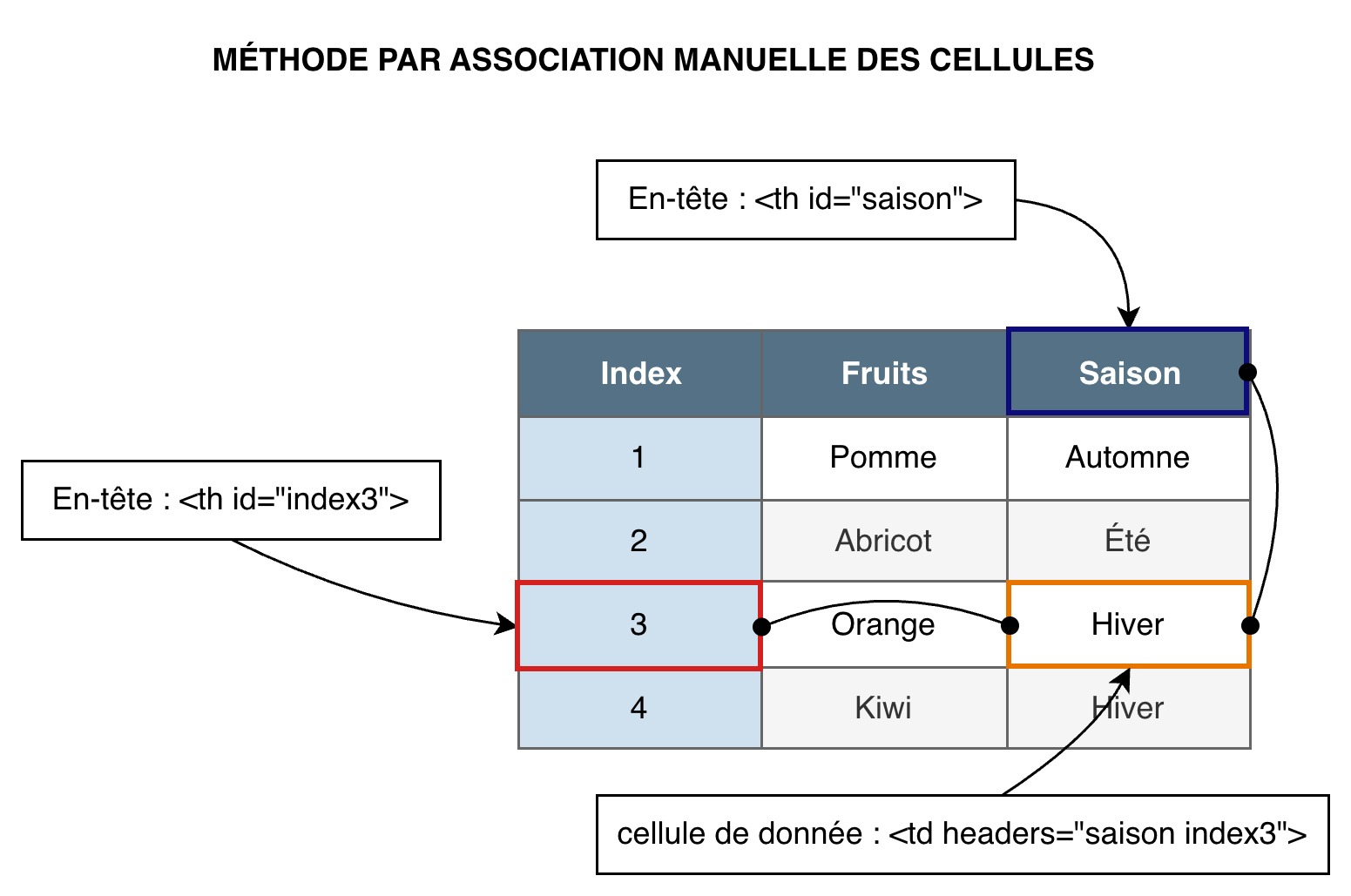
Description du schéma « Méthode par périmètre d’action »
Ce schéma utilise le même tableau de trois colonnes et cinq lignes que l’exemple précédent (liste de fruits et leur saison).
La première cellule de la troisième colonne est nommée « Saison » et le schéma précise que c’est un en-tête avec un identifiant (ID) « fruits ». La quatrième cellule de la première colonne contient l’index « 3 » et le schéma précise que c’est un en-tête avec un identifiant (ID) « index 3 ».
Le schéma précise que la quatrième cellule de la troisième colonne est une cellule de donnée qui porte un attribut headers listant les deux identifiants, séparés par un espace. Le schéma contient aussi deux flèches reliant cette cellule (dont le contenu est « Hiver ») aux deux en-têtes « Saison » et « 3 », pour expliciter le lien créé par l’usage de leurs identifiants.
Avec cette méthode, il faut intervenir sur toutes les cellules du tableau, ce qui la rend assez lourde à mettre en place (sans compter qu’il faut aussi définir des identifiants uniques à chaque en-tête).
J’aimerais vivre en théorie, parce qu’en théorie tout se passe bien
Avec des méthodes aussi complètes, en théorie nous devrions pouvoir garantir l’accessibilité de n’importe quel tableau assez facilement, quelle que soit leur complexité !
… sauf que l’implémentation de ces spécifications est imparfaite et irrégulière !
Tout va (à peu près) bien tant que l’on reste sur des tableaux simples, mais dès qu’on commence à tester des tableaux complexes, certaines combinaisons navigateurs/lecteurs d’écran commencent à « se prendre les pieds dans le tapis », même quand le HTML du tableau respecte à la lettre les spécifications.
L’enjeu va donc être de réussir à définir les motifs de tableau qui fonctionnent à peu près correctement (ou échouent le mieux, question de point de vue). Pour cela, j’ai testé les différents exemples fournis dans cet article sur un panel de test restreint, détaillé en annexe, que j’ai voulu le plus représentatif possible8 .
Note : selon mes tests, les tableaux de plus de quelques lignes pourraient être difficiles à consulter pour les personnes qui utilisent Android. En effet, TalkBack9 ne restituait jamais les en-têtes de colonnes durant mes tests (sur la version Android de Firefox, c’était encore pire : il n’annonçait même pas le numéro des colonnes !10 ).
Ce qui marche : tableaux avec des colonnes fusionnées
Cas d’usage
Pour les colonnes fusionnées, le cas le plus fréquent est probablement celui où nous avons besoin de regrouper des colonnes de données en différentes catégories qui formeront des « super-colonnes ». Imaginons un cas simple avec un tableau commençant par deux lignes d’en-têtes :
- la première ligne comporte des en-têtes fusionnés, nos catégories, valables pour plusieurs colonnes ;
- les en-têtes de la seconde ligne indiquent les données correspondant à chaque colonne.
| Produit | Caractéristiques | |||
|---|---|---|---|---|
| Nom | Numéro de modèle | Norme | Dimensions | Couleur |
| Lambda 2000 | DCMU45E | ECC 455 | 45 × 90 × 40 cm | Métal |
| Dural 2 | XOCH025 | ECC 455 | 70 × 90 × 40 cm | Blanc |
| Malin Malin | JMA45XX | ISO 9001:2015 | 70 × 75 × 80 cm | Blanc |
| Malin x3 | JMA56XX | ISO/DIS 9001 | 60 × 30 × 75 cm | Rouge |
Dans ce tableau, les en-têtes sont structurés ainsi :
<thead>
<tr>
<th colspan="2" scope="colgroup">Produits</th>
<th colspan="3" scope="colgroup">Caractéristiques</th>
</tr>
<tr>
<th scope="col">Nom</th>
<th scope="col">Numéro de modèle</th>
<th scope="col">Norme</th>
<th scope="col">Dimensions</th>
<th scope="col">Couleur</th>
</tr>
</thead>La restitution
Les colonnes fusionnées sont assez bien restituées par les lecteurs d’écrans (du moins pas plus mal que les colonnes d’un tableau simple… oui Android, c’est de toi dont je parle !). Sur les navigateurs testés sur ordinateur, les deux niveaux d’en-têtes sont bien restituées lorsqu’on change de cellules.
Quelques comportements qui peuvent surprendre mais sont parfaitement normaux :
- la colonne fusionnée n’est énoncée que lorsqu’on « entre dedans » : dans mon exemple, « Produits » ne sera annoncé que lorsque j’arrive dans une cellule de la colonne « Nom » et non lorsque je passe sur la colonne « Numéro de modèle » ;
- l’association par « périmètre d’action » (scope) ne crée pas de liens hiérarchiques entre le premier niveau d’en-tête et le second11
:
- ainsi quand nous arrivons sur « Caractéristiques », l’en-tête de niveau 2 « Norme » est aussi restitué,
- par contre les autres en-têtes des autres colonnes sur lesquelles s’étend « Caractéristiques » ne sont pas restitués à ce moment-là (pour l’algorithme de parcours du tableau, nous sommes sur la colonne trois et seuls les en-têtes déclarés dans cette colonne doivent être restitués).
Je trouve les deux derniers points peu satisfaisants (difficile de comprendre la structure du tableau sans une certaine hiérarchisation des en-têtes), mais c’est le comportement attendu.
Note : C’est pour cela qu’il est nécessaire de décrire la structure des tableaux complexes (voir W3C WAI, Caption and Summary in Tables Tutorial ou HTML Specifications for tables - Description techniques).
Les colonnes fusionnées peuvent donc être utilisées, avec quelques précautions.
Support incomplet sur iOS
Sur iOS, les niveaux multiples d’en-tête de colonne sont mal restitués. Dans notre exemple, seuls les premiers en-têtes « Produit » et « Dimensions » sont restitués, laissant l’utilisateur ou l’utilisatrice se débrouiller avec les numéros de colonne et sa mémoire pour se souvenir à quoi correspond chaque cellule. C’est mieux que sur Android mais pas tout à fait satisfaisant non plus.
Méfiance avec les colonnes « orphelines »
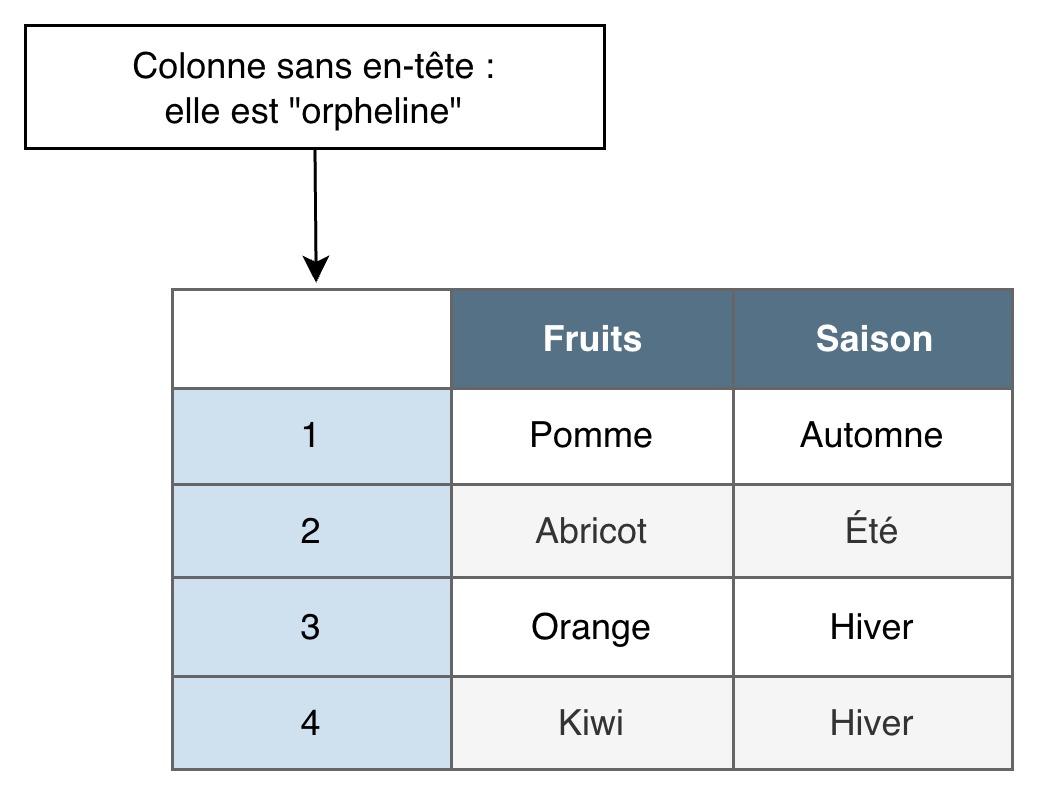
Description du schéma « Colonne orpheline »
Ce schéma utilise le même tableau de trois colonnes et cinq lignes que nos exemples en début d’article (liste de fruits et leur saison).
La principale différence est qu’ici la première cellule de la première colonne est vide. Les cellules des lignes suivantes contiennent toujours leurs index, numérotés de 1 à 4. Le schéma précise que cette colonne d’index n’ayant aucun en-tête de colonne, elle est « orpheline ».
En effet, si vous omettez d’assigner un en-tête à une de vos colonnes, certains motifs de tableaux seront étrangement restitués sur certains navigateurs. J’ai ainsi eu un souci avec Chrome et Safari sur Mac (avec VoiceOver). La restitution de mon tableau de test (voir schéma ci-dessus) était incohérente :
- soit un des en-têtes de colonne existants était assigné (à tort) à ma colonne orpheline,
- soit un de mes en-têtes de colonne se retrouvait affublé d’une association incohérente avec un des en-têtes de lignes du tableau.
Mon problème ? J’avais désigné les cellules de ma colonne « orpheline » comme des en-têtes de lignes, et Chrome et Safari sur Mac n’ont pas trop apprécié !
Après quelques recherches additionnelles, voici les conditions à suivre pour ne pas avoir de mauvaises surprises avec des cellules orphelines :
- si vous avez une colonne orpheline : ne placez jamais d’en-tête de ligne dedans ;
- les cellules vides en haut de votre colonne orpheline doivent être des cellules de données (
<td>), jamais des cellules d’en-tête (<th>) ; - et n’oubliez pas de vous poser la question : « ai-je besoin de cette colonne que je n’arrive pas à nommer ? ».
Remarque : on pourrait d’ailleurs critiquer la pertinence de mon choix : un index numérique n’est pas forcément un en-tête de ligne très pertinente.
Bien choisir ses en-têtes de lignes
En dehors d’éviter les anomalies de restitutions sur certains tableaux, il est important de bien choisir ses en-têtes de lignes (<th scope="row">). Celles-ci sont l’un des deux moyens d’identifier à quelle ligne se rapporte la cellule visitée lorsqu’on se déplace verticalement dans le tableau, l’autre moyen étant le décompte des lignes.
Inutile de vous dire que sur un tableau de plus de quelques lignes, le décompte des lignes peut être considéré comme insuffisant pour se repérer et différencier deux lignes.
Il faut donc choisir des en-têtes de lignes réunissant les conditions suivantes :
- uniques (si la donnée se répète sur d’autres entrées de notre tableau, le risque de confusion est grand) ;
- mémorables et identifiables.
Il est possible de désigner plusieurs cellules d’en-tête pour une ligne (notamment pour assurer l’unicité de la dénomination de chaque ligne) mais attention :
- ces en-têtes se répéteront à chaque navigation verticale, si trop de cellules ont été intégrées comme des en-têtes de ligne, la restitution peut devenir pénible ;
- nous l’avons déjà évoqué, Safari et VoiceOver sur iPhone ne restituent actuellement qu’un seul en-tête par colonne et par ligne.
Pour revenir sur notre exemple de liste de fruits, j’aurais probablement dû utiliser les cellules de la colonne « Fruits » comme en-tête de ligne : si je navigue verticalement dans la colonne « Saison », il est beaucoup plus intéressant de m’entendre restituer « Pomme » ou « Abricot » que « 1 » ou « 2 ».
| Fruits | Saison | |
|---|---|---|
| 1 | Pomme | Automne |
| 2 | Abricot | Été |
| 3 | Orange | Hiver |
| 4 | Kiwi | Hiver |
Description du tableau
Ce tableau de trois colonnes et cinq lignes contient une liste de fruits et indique leur saison :
- la première colonne sert à numéroter la liste de fruits ;
- la deuxième colonne liste les fruits ;
- la troisième colonne indique la saison de chaque fruit.
Ce qui marche : tableaux avec des lignes fusionnées
Cas d’usage
Pour les lignes fusionnées, au lieu de regrouper des colonnes de données, notre cas d’usage classique va nécessiter de regrouper des entrées de notre tableau ensemble, pour mettre en avant une donnée que ces entrées ont en commun.
| Groupe | Élève | Français | Math | Sciences | Moyenne |
|---|---|---|---|---|---|
| Groupe A | Lina Ben Saïd | 15 | 14 | 16 | 15,0 |
| Thimothée Laurent | 12 | 11 | 13 | 12,0 | |
| Maéva Rodrigues | 14 | 13 | 14 | 13,7 | |
| Groupe B | Élodie Martin | 16 | 14 | 15 | 15,0 |
| Enzo Moreau | 15 | 17 | 16 | 16,0 | |
| Riya Patel | 18 | 13 | 14 | 15,0 |
Description du tableau
Ce tableau contient une liste d’élèves et leur moyenne dans trois matières. Les élèves sont répartis en deux groupes :
- la première colonne contient deux grandes cellules, une par demi-groupe ;
- la deuxième colonne liste les élèves de chaque groupe ;
- la troisième colonne indique la moyenne en français de chaque élève ;
- la quatrième colonne indique la moyenne en mathématiques de chaque élève ;
- la cinquième colonne indique la moyenne en sciences de chaque élève ;
- la sixième colonne indique la moyenne générale de chaque élève.
Dans ce tableau, les en-têtes des lignes sont marqués ainsi :
<tr>
<th colspan="3" scope="rowgroup">Groupe B</th> <!-- Le nombre dans l’attribut colspan dépend du nombre d’élèves dans ce groupe -->
<th scope="row">Nom d’un élève</th>
<!-- notes -->
</tr>
<tr>
<!-- pas de cellules pour la première colonne -->
<th scope="row">Nom d’un autre élève</th>
<!-- notes -->
</tr>La restitution
Les lignes fusionnées sont assez bien restituées par les lecteurs d’écrans (comme pour les colonnes fusionnées).
On retrouve les mêmes comportements un peu surprenants que l'on avait avec les colonnes fusionnées.
Les lignes fusionnées peuvent donc être utilisées, avec les mêmes précautions que les colonnes fusionnées.
Ce qui marche moins bien : le mélange de colonnes et lignes fusionnées
Maintenant que nous savons faire des tableaux avec des colonnes ou des lignes fusionnées, il est tentant de mélanger, d’ajouter un peu de complexité.
Sur beaucoup de combinaisons navigateur/lecteurs d’écran, la restitution sera satisfaisante (tant qu’on évite l’écueil des colonnes « orphelines »), mais quelques comportements bizarres observés avec VoiceOver (en combinaison avec Safari ou Chrome) m’amènent à recommander de se tenir à un seul type de fusion : colonnes ou lignes.
En effet sur Mac, Chrome et Safari m’ont fait d’étranges associations sur mes en-têtes de colonnes, les associant parfois à des en-têtes de lignes qui ne sont ni sur la même colonne ni sur la même ligne. Selon la structure de votre information cela peut être plus ou moins perturbant, mais en général je recommanderais d’éviter de placer vos utilisateurs et vos utilisatrices dans cette situation.
Si vous souhaitez voir jusqu’à quel point on peut rendre illisible la restitution d’un tableau en fusionnant colonnes et lignes, je vous invite à lire cet article d’Adrian Roselli (oui, encore lui) : Avoid Spanning Table Headers.
Et si je fusionne seulement des cellules de données ?
Contrairement aux cellules d’en-têtes, la fusion de cellules de données au sein du tableau ne risque de fausser la compréhension de la structure du tableau par les lecteurs d’écran. En revanche elles peuvent déstabiliser l’utilisateur ou l’utilisatrice lors de sa navigation dans le tableau.
Avec la plupart des lecteurs d’écrans, les cellules de données fusionnées ne sont lues que lorsque l’utilisateurice arrive sur la première de nos cellules fusionnées : lorsque l’utilisateurice poursuit sa navigation et qu’iel arrive à la colonne ou ligne sur laquelle une cellule a été étendue, la cellule est sautée et iel est envoyé directement à la colonne/ligne suivante.
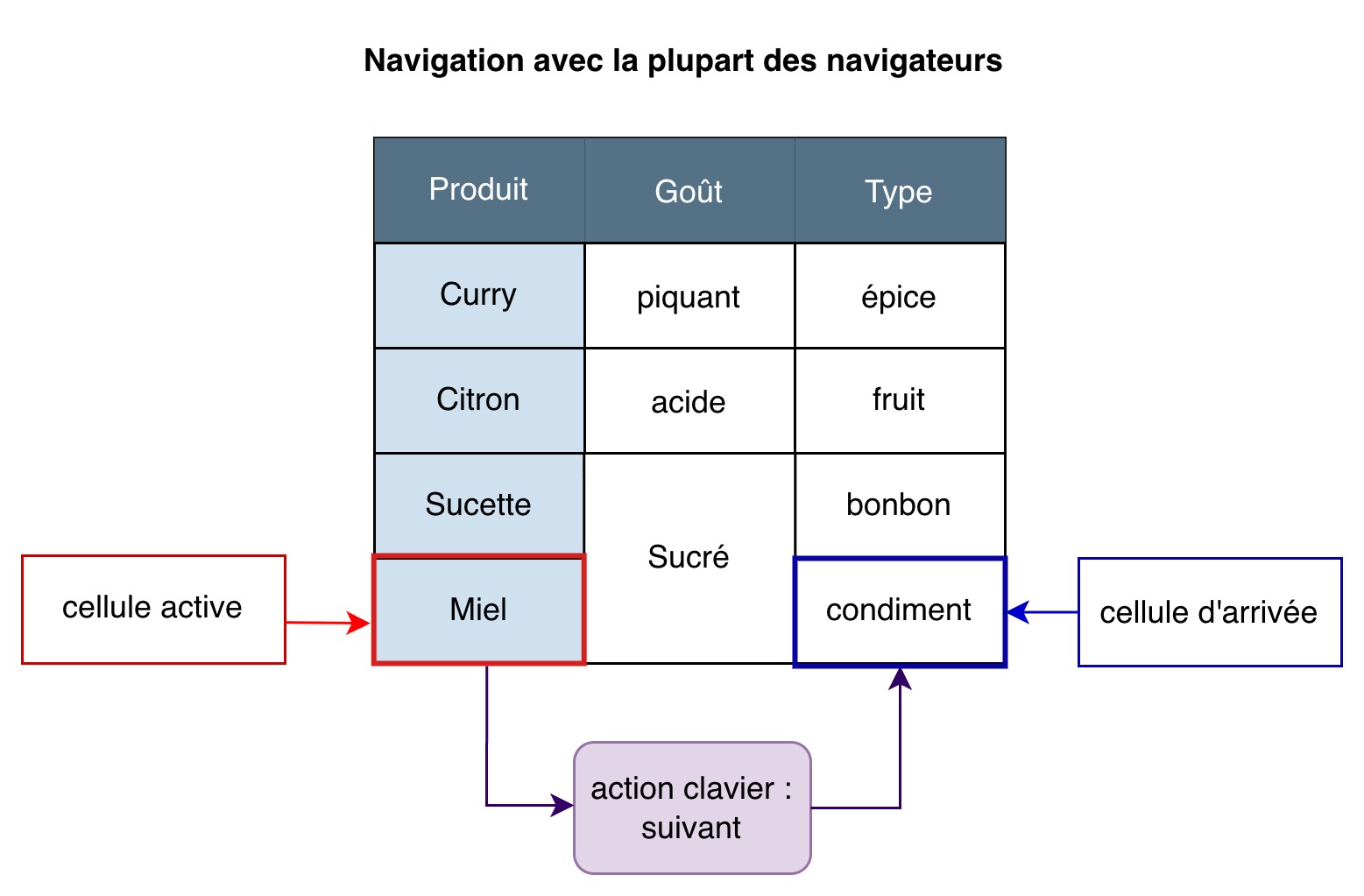
Description du schéma « Navigation avec la plupart des lecteurs d’écran »
Un tableau de trois colonnes et cinq lignes. La première colonne affiche des produits alimentaires (en-tête « Protduit ») ; la deuxième et la troisième colonnes décrivent respectivement le goût et le type de chaque produit (en-têtes « Goût » et « Type »).
Les cellules des lignes 4 et 5 de la colonne « Goût » sont fusionnées pour afficher les informations suivantes :
- Ligne 4 : produit « Sucette » ; goût « Sucré » ; Type « bonbon ».
- Ligne 5 : produit « Miel » ; goût « Sucré » ; Type « condiment ».
Le schéma présente le comportement d’un lecteur d’écran lors de la navigation dans la ligne 5 : en partant de la cellule « Miel », l’action pour passer à la cellule suivante au clavier nous amène sur la cellule « condiment », ignorant la cellule fusionnée intermédiaire « Sucré ».
Avec le lecteur d’écran NVDA, la navigation est plus satisfaisante : les cellules fusionnées ne sont pas sautées et la navigation se poursuit bien dans la bonne colonne/ligne. En revanche, la restitution peut surprendre l’utilisateurice (le lecteur d’écran ne va pas restituer l’en-tête de la colonne/ligne dans laquelle se trouve l’utilisateurice mais celle de la cellule avec laquelle la cellule ciblée a été fusionnée).
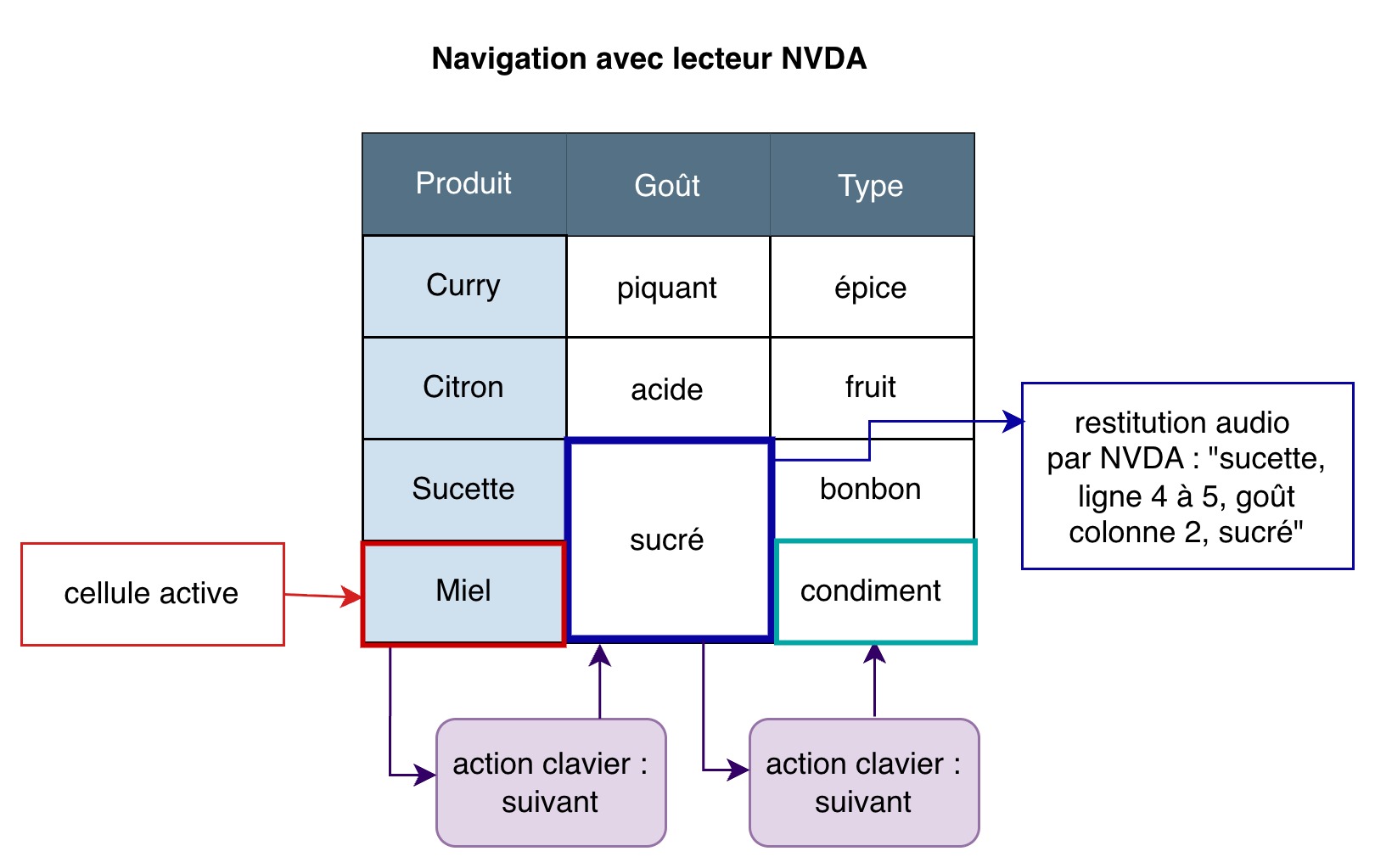
Description du schéma « Navigation avec lecteur NVDA »
À partir du même exemple du tableau précédent affichant le goût et type de différents produits alimentaires, le schéma présente le comportement de NVDA lors de la navigation dans la ligne 5.
En partant de la cellule « Miel », l’action pour passer à la cellule suivante au clavier nous amène sur la cellule « sucré » restituée comme suit : « sucette, ligne 4 à 5, goût colonne 3, sucré ». L’action pour passer à la cellule suivante amène à la cellule « condiment ».
On se rend compte que la cellule fusionnée retourne la mauvaise valeur d’en-tête de ligne : « Sucette » (ligne 4) au lieu de « Miel » (ligne 5).
Si l’on se base sur les spécifications, ces comportements sont relativement normaux, mais l’expérience utilisateur n’est pas très satisfaisante.
Ma recommandation : avant d’appliquer des cellules fusionnées, s’interroger sur leurs bénéfices par rapport à une simple répétition du contenu dans chaque ligne/colonne :
- si le contenu est très long, il peut être intéressant d’éviter la répétition ;
- s’il est assez court, il peut être préférable de conserver des cellules indépendantes.
Et l’association manuelle ? Si j’ai un tableau très compliqué et que je suis motivé, ça marche ?
En ce qui concerne l’association manuelle avec des identifiants et des attributs headers, les navigateurs et lecteurs d’écran gèrent aussi bien cette méthode d’intégration que celle par « périmètre d’action » : elle fonctionne bien (sauf sur Android) tant qu’on évite de fusionner des en-têtes de colonnes et des en-têtes de lignes dans le même tableau, ainsi que les colonnes « orphelines ».
Elle marche aussi bien que la méthode par « périmètre d’action », pas mieux.
Mais compte tenu de la lourdeur de sa mise en place (et de la facilité à faire une erreur), elle n’est pas très intéressante sur les cas relativement simples que nous avons présentés jusqu’ici12 . C’est sur les tableaux les plus complexes qu’elle devrait briller… Sauf que plus un tableau est complexe, plus le risque d’anomalies de restitution est grand ! (Sans compter qu’à partir d’un certain niveau de complexité, on peut s’interroger sur la pertinence du tableau en tant que vecteur d’information).
Ma recommandation :
- s’efforcer de trouver des alternatives pour réduire la complexité d’un tableau ;
- si ce n’est pas pas possible/si vous tenez absolument à votre tableau : testez-le ! Testez-le avec le plus de combinaisons navigateurs/lecteurs d’écrans possible, afin de repérer et évaluer les éventuelles anomalies de restitution.
Simplifier ses tableaux pour les améliorer
Les limites techniques que nous avons explorées dans la partie précédente nous forcent à simplifier nos tableaux pour garantir leur accessibilité au plus grand nombre. Mais ces contraintes peuvent aussi être des opportunités de les améliorer pour tous. Dans cette partie, nous allons parcourir ensemble quelques cas de tableaux (trop) complexes, et les façons dont nous pouvons optimiser leur restitution.
Le tableau en « strates »
Ici nous avons initialement scindé notre tableau en plusieurs « strates » de données, regroupées en thématiques. C’est visuellement satisfaisant et les voyant·es parmi nous comprennent bien la structure de l’information, mais même en prenant mille précautions dans notre intégration, le résultat est compliqué à suivre dans un lecteur d’écran !
Toutes mes excuses aux personnes qui utilisent un lecteur d’écran, le tableau qui suit est pénible (promis, les prochains seront plus agréables). Si vous le souhaitez, vous pouvez évitez ce tableau et passer à la suite de l’article.
| Matricule | Nom | Emploi | Responsable |
|---|---|---|---|
| Direction des Systèmes d’Information (DSI) | |||
| 2315 | Abdel Cherif | Développeur | Nathalie Nguyen |
| 2475 | Samia Réno | Admin. Système | Nathalie Nguyen |
| Service Marketing | |||
| 1985 | Marine Sousa | Cheffe de projet | Philippe Garcia |
| 3485 | Thibault Valentin | Commercial | Philippe Garcia |
Description du tableau
Ce tableau contient une liste d’employé·es, répartis par services :
- la première colonne indique le matricule de chaque employé·e ;
- la deuxième colonne indique le nom de chaque employé·e ;
- la troisième colonne indique le rôle (emploi) de chaque employé·e ;
- la quatrième colonne indique le responsable hiérarchique de chaque employé·e.
Le tableau est découpé en deux parties (une par service) chaque service est indiqué par une cellule d’en-tête occupant toute la ligne.
Retourner au texte avant le tableau Pour ce genre de cas, deux options s’offrent à nous, qui pourront être plus ou moins adaptées selon l’usage que nous faisons de ce tableau :
- l’aplanir ;
- le découper.
Aplanir le tableau
Aplanir le tableau consiste à « rétrogader » nos strates de supers en-têtes découpant le tableau en une simple colonne de données :
| Matricule | Nom | Emploi | Responsable | Service |
|---|---|---|---|---|
| 2315 | Abdel Cherif | Développeur | Nathalie Nguyen | DSI |
| 2475 | Samia Réno | Admin. Système | Nathalie Nguyen | DSI |
| 1985 | Marine Sousa | Cheffe de projet | Philippe Garcia | Marketing |
| 3485 | Thibault Valentin | Commercial | Philippe Garcia | Marketing |
Découper le tableau
Si nous avons ressenti le besoin d’insérer des « strates », peut-être est-ce parce que nous avons plusieurs sets de données (plus ou moins) indépendants à afficher. Dans ce cas, pourquoi ne pas le découper en plusieurs tableaux ?
Note : par défaut ces tableaux ne seront pas aussi joliment alignés que dans notre premier exemple (les largeurs des colonnes dépendant de leur contenu), mais avec un peu de CSS il ne devrait pas être trop compliqué d’harmoniser tout cela !
| Matricule | Nom | Emploi | Responsable |
|---|---|---|---|
| 2315 | Abdel Cherif | Développeur | Nathalie Nguyen |
| 2475 | Samia Réno | Admin. Système | Nathalie Nguyen |
| Matricule | Nom | Emploi | Responsable |
|---|---|---|---|
| 1985 | Marine Sousa | Cheffe de projet | Philippe Garcia |
| 3485 | Thibault Valentin | Commercial | Philippe Garcia |
Le tableau condensé
La tentation est souvent forte de condenser notre tableau à l’extrême, généralement pour des raisons esthétiques, parfois jusqu’au point où l’on sort presque du tableau de données.
C’est le cas dans mon prochain exemple : les résultats des élections d’un CSE (comité social et économique) fictif (listes, nombre de sièges obtenus, détails des votes…) ont été réorganisés au point que la structure de l’information n’est plus visible (l’auteur se repose sur la capacité de son lectorat voyant à deviner le lien en fonction du contexte).
Mise en garde : si vous utilisez un lecteur d’écran, l’intégration du tableau suivant est farfelue et celui-ci est absolument incompréhensible (les tableaux qui le suivent contiennent la même information et sont mieux construits). Si vous le souhaitez, vous pouvez évitez ce tableau et passer à la suite de l’article.
| Tête de liste | % de voix | |
|---|---|---|
| Martine Laval | 9 sièges | 40 % |
| CGT | (120) | |
| Aboubacar Ndiaye | 7 sièges | 32 % |
| CFDT | (96) | |
| Daphnée Cho | 6 sièges | 28 % |
| Synergie intersyndicale | (84) | |
Description du tableau
Ce tableau présente les résultats des différentes listes et le nombre de sièges obtenus. Le tableau est structuré en trois colonnes et par groupe de deux lignes.
Les trois colonnes contiennent plusieurs informations :
- la première colonne sous l’en-tête « Tête de liste » contient le nom de la tête de liste et le nom de la liste ;
- la deuxième colonne, toujours sous l’en-tête « Tête de liste » indique le nombre de sièges obtenus ;
- la troisième colonne « pourcentage de voix » contient le pourcentage de voix obtenues, ainsi que le décompte exact.
Pour chaque groupe de deux lignes :
- la première ligne contient le nom de la tête de liste, le nombre de sièges et le pourcentage de voix ;
- la seconde ligne contient le nom de la liste, le nombre de sièges (la cellule s’étend sur les deux lignes) et le nombre exact de voix obtenues.
Retourner au texte avant le tableau
Revenir à un tableau de données brutes
Pour comprendre pourquoi les personnes qui ont conçu ce tableau sont arrivées à ce résultat (et leur proposer des alternatives qui les satisferont), il faut repartir de la donnée brute :
| Tête de liste | Nom de la liste | Nombre de sièges obtenus | Nombre de voix | Pourcentage de voix |
|---|---|---|---|---|
| Martine Laval | CGT | 9 sièges | 120 | 40 % |
| Aboubacar Ndiaye | CFDT | 7 sièges | 96 | 32 % |
| Daphnée Cho | Synergie intersyndicale | 6 sièges | 84 | 28 % |
Nous avons donc :
- deux informations permettant d’identifier la liste :
- le nom de la tête de liste ;
- le nom de la liste ;
- le résultat de l’élection (le nombre de sièges attribués à chaque liste) ;
- les données de dépouillement (qui justifient le résultat) :
- le pourcentage de voix obtenu (sur le nombre de votants) ;
- le nombre de voix récolté par chaque liste.
Remarque : il semble que pour notre cible, l’élément déterminant pour identifier une liste n’est pas son nom mais sa tête de liste (vu que c’est cette information qui a été choisie comme en-tête de ligne).
Simplifier en regroupant les données
Si nous souhaitons conserver une structure de tableau de données mais en le condensant, nous pouvons regrouper plusieurs données dans une même cellule et ainsi réduire le nombre de colonnes (tout en nous donnant un peu de latitude pour organiser visuellement ces données). Mais pour que la restitution reste cohérente, il faut aussi retravailler la dénomination des colonnes restantes pour qu’elle soit pertinente pour l’ensemble de la donnée qu’elle contient.
| Liste et tête de liste | Sièges obtenus | Suffrages |
|---|---|---|
| Martine Laval (CGT) | 9 sièges | 40 % (120 voix) |
| Aboubacar Ndiaye (CFDT) | 7 sièges | 32 % (96 voix) |
| Daphnée Cho (Synergie intersyndicale) | 6 sièges | 28 % (84 voix) |
Avec cette structure simplifiée, le tableau est moins monotone qu’un simple tableau de données mais reste cohérent lors de la restitution.
Remarques :
- Notre en-tête fonctionne si notre lectorat a le contexte culturel nécessaire pour déduire le nom de la tête de liste et le nom de la liste elle-même.
Dans certains cas, il peut être nécessaire d’ajouter des libellés (ou des éléments graphiques accompagnés de textes masqués) pour expliciter les données dans chaque cellule d’en-têtes. - Comme nous avons placé le nom de la liste et celui de sa tête de liste dans l’en-tête de ligne, la restitution sera un peu bavarde quand l’utilisateur ou l’utilisatrice changera de ligne (l’intégralité du texte de l’en-tête étant lu).
- C’est d’ailleurs pour cela que nous n’avons pas davantage compacté notre tableau en intégrant le nombre de sièges dans l’en-tête de ligne.
- Note : une autre solution aurait été d’encore plus simplifier le tableau, en supprimant les en-têtes de ligne et ainsi le réduire à deux colonnes de super-cellules de données.
Alternative : abandonner la structure de tableau
Une autre option que nous aurions pu explorer est de tout simplement abandonner la notion de tableau et simplement agencer les différentes informations avec du CSS. Cette approche est très souple mais attention ! Sans la structure du tableau pour informer les personnes qui utilisent un lecteur d’écran, il sera probablement nécessaire d’ajouter des textes cachés pour clarifier les informations restituées.
Par exemple :
- sans structure de tableau, pour la première ligne, les lecteurs d’écrans restitueront probablement (à condition que l’ordre des libellés dans le HTML soit à peu près logique) : « Martine Laval CGT 9 sièges 40 % 120 voix » ;
- pour améliorer la compréhension, il faudra probablement agrémenter notre texte mise en forme comme un tableau de quelques libellés masqués pour obtenir une restitution plus explicite : « Martine Lavel et la liste CGT 9 sièges au CSE, suffrages récoltés 40 % avec 120 voix ».
(Dans certains cas, il peut être plus simple de masquer complètement le bloc correspondant aux lecteurs d’écrans et de fournir en remplacement un texte masqué décrivant précisément les informations… mais attention à ne pas oublier de mettre à jour ce texte lorsque les données du tableau sont modifiées !).
Attention ! Pour s’assurer que le résultat est bien compréhensible, il est nécessaire de tester avec plusieurs navigateurs et lecteurs d’écran ce genre d’intégrations exotiques.
Alternative : tableau de données brutes lourdement remanié en CSS
La dernière alternative que je n’ai pas explorée ici est de partir de notre tableau de données brutes et d’en conserver la structure et d’ensuite le « recomposer » à force de CSS (avec l’API flexbox) et de masquage accessible (voir le dernier article de Gaël Poupard sur le sujet).
Mais cette approche a plusieurs inconvénients :
- elle est très spécifique (il vous faudra probablement faire du CSS spécifique à chaque configuration de tableau) ;
- comme pour toute intégration « exotique » :
- des tests multi-contextes (appareils, navigateurs,…) seront nécessaires pour garantir un affichage correct en toute situation ;
- cette intégration sera aussi moins robuste dans le temps (plus de risques de régressions dues à une évolution des navigateurs ou de notre propre code).
Conclusion
Nous sommes loin d’avoir abordé tous les cas de figure possibles mais j’espère que les quelques cas étudiés vous auront donné les éléments de réflexions nécessaires pour concevoir et intégrer des tableaux vraiment accessibles, quelles que soient la richesse et la complexité des informations à fournir.
Si vous ne deviez retenir qu’une seule chose, ce serait :
Faites simple ou préparez-vous à une batterie de tests.
Mais si une liste de points à retenir plus détaillée vous intéresse, alors :
- un tableau sert à communiquer : interrogez-vous toujours sur l’information que vous voulez transmettre, sur ce qui lie les données entre elles. L’intention est clef pour produire des contenus accessibles ;
- cherchez la simplicité :
- un tableau simple est un tableau facile à comprendre ;
- plus un tableau est simple, plus il est robuste (moins de risque d’anomalies de restitution) ;
- ne pas hésiter à redécouper en plusieurs tableaux ;
- pas de colonnes orphelines : essayez d’avoir la même densité d’en-tête sur vos colonnes ;
- cellules d’en-têtes fusionnées, mieux vaut choisir : colonnes ou lignes ;
- intégration :
- optez pour l’attribut scope :
- simple et rapide à intégrer ;
- les tableaux trops complexes pour l’utiliser seront de toute manière probablement mal restitués ;
- l’association manuelle (avec le couple
id/headers) fonctionne aussi :- mais elle est plus lourde à intégrer et maintenir ;
- elle permet de gérer des cas très complexes mais :
- il est probable que ces tableaux soient mal restitués ;
- il sera nécessaire de faire des tests poussés pour vérifier le résultat ;
- autres alternatives (données non structurées, structure simple remaniée en CSS) : si la complexité de votre tableau vous force dans ces extrémités, rappelez-vous tout de même de bien le tester avec plusieurs configurations.
- optez pour l’attribut scope :
Annexe : Panel de test
Pour mes tests, j’ai utilisé les appareils et logiciels suivants :
| Appareil | Système d’exploitation | Navigateurs | Lecteur d’écran |
|---|---|---|---|
| Macbook Pro M1 14"pouces | MacOS 15.6.1 (Sequoia) |
|
VoiceOver (Mac) |
| Lenovo Yoga | Windows 10 |
|
NVDA |
| iPhone 13 | iOS 18.6.2 | Safari | VoiceOver (iOS) |
| One Plus 8T | Android 14 |
|
TalkBack |
Crédits
Les schémas de cet article ont gracieusement été réalisés par Myriam Nguyen-The.
- Les capacités du CSS en termes de positionnement étaient assez limitées avant l’arrivée des modules de niveau 3 (CSS3) au début des années 2000. Retour au texte 1
- Image Ready était un logiciel compagnon de Photoshop qui découpait nos designs en de jolis tableaux (inaccessibles) d’images prêtes à l’emploi. À la fac on nous apprenait même à réaliser des sites (nuls) intégralement avec ce logiciel. Retour au texte 2
-
Si vous utilisez encore des tableaux pour simplement faire de la mise en page, j’espère qu’au moins vous leur ajoutez un attribut
role="presentation". Retour au texte 3 - C’est le risque quand on s’intéresse à un champ d’expertise en constante évolution pendant des décennies, même quand l’on tombe sur des ressources comme le blog d’Adrian Roselli, méticuleusement mis à jour par son auteur au fil des années : il finit par être difficile de savoir quel article, quelle technique reste d’actualité ou est obsolète. Retour au texte 4
- Motif : ma traduction personnelle du terme anglais pattern. Retour au texte 5
-
Critères sur la struture de l’information :
- WCAG : critère de succès 1.3.1 Information et relations (générique, ne concerne pas que les tableaux) ;
- RGAA, deux critères spécifiques aux tableaux de données : critère 5.6 et critère 5.7.
-
Les structures de tableaux simples standards sont :
- une première ligne d’en-têtes de colonne ;
- une première colonne d’en-tête de ligne ;
- ou les deux, avec la première cellule du tableau étant un en-tête de colonne.
- Panel de test représentatif (dans la mesure des moyens disponibles) : le panel utilisé pour mes tests couvre les systèmes/appareils les plus connus et disponibles dans mon entourage. Il est tout à fait possible que vous repériez des anomalies de restitutions sur des configurations non couvertes dans mes tests. Retour au texte 8
- Le lecteur d’écran intégré d’Android. Retour au texte 9
- Non-restitution des en-têtes par TalkBack : il est tout à fait possible que ce problème ne soit pas une anomalie mais une question de réglage de la fonction. N’étant pas un utilisateur régulier d’Android, je reconnais ne pas bien connaître son lecteur d’écran intégré. Retour au texte 10
- En tant qu’humain nous créons implicitement des liens hiérarchiques entre les en-têtes affichés en premier et ceux affichés ensuite. Ce n’est pas le cas de la machine. Pour l’algorithme générant l’accessibility tree, chaque en-tête est considéré comme ayant la même importance, quelle que soit sa position dans une colonne ou une ligne. Retour au texte 11
- Bien que la méthode par association manuelle des cellules ne soit pas la plus simple à utiliser, elle est aussi bien supportée que la méthode par périmètre d’action. Si pour des raisons techniques vous êtes contraint·e de l’utiliser (par exemple, une limitation imposée par les outils d’édition de votre CMS), il est OK de l’utiliser, avec prudence. Retour au texte 12
Il n’est plus possible de laisser un commentaire sur les articles mais la discussion continue :